열린마당



2013년 12월 02일 (월)
ⓒ 지디넷코리아, 김우용 기자 yong2@zdnet.co.kr
SK텔레콤은 올해 이동통신망 인프라 관리체계에 대대적인 수술을 감행했다. 수많은 장비에서 생성되는 로그 데이터를 실시간으로 수집, 분석해 망관리의 품질을 높이기 위한 사업이었다. SK텔레콤은 이를 위해 기존에 마련했던 하둡 및 여러 빅데이터 요소기술을 재정비하고, 체계적인 플랫폼 구축에 집중했다.
이 같은 작업에 참여했던 홍태희 SK텔레콤 네트워크운용본부 NMC 매니저가 지난달 본지가 개최한 제10회 어드밴스드컴퓨팅컨퍼런스(ACC)에서 SK텔레콤의 네트워크관리 인프라에 적용한 빅데이터 기술을 소개했다.
SK텔레콤은 2G, WCDMA, 4G LTE, 와이브로, 와이파이 등 다양하고 복잡한 이동통신망을 운영한다. 통신품질은 사업 성패를 결정짓는 핵심 요소인 만큼 각각의 망을 관리하는 네트워크관리시스템(NMS)도 매우 중요하다.

SK텔레콤의 NMS 운영은 1초라도 빨리 장애의 원인을 찾아내는 것이 핵심이다. 통신망 장애를 정상화하는데 걸리는 시간을 얼마나 최소화하느냐가 통신사업자로서 SK텔레콤 본연의 경쟁력과 직결되는 탓이다.
SK텔레콤의 새 NMS는 각 이동통신망을 구성하는 장비에서 생성되는 로그 데이터를 수집, 처리, 저장, 분석하는 흐름으로 구성돼 있다. 홍태희 매니저가 관여한 분야는 실시간으로 로그를 수집해 분단위 통계를 내는 영역이다. 그는 하둡을 비롯한 현존하는 여러 오픈소스 기술을 이용해 SK텔레콤 NMS 요구사항에 부합하는 플랫폼을 구축했다.
일단 SK텔레콤 NMS의 최우선 전제는 데이터 수집이다. 기술적으로 각 장비에 부하를 주지 않는 방법으로 데이터를 모으고, 중간에 특정 부분의 수집작업이 끊어지지 않도록 하는 게 쉽지 않다.
기존 NMS는 장비에 대한 의존도가 컸다. 분단위 통계를 위해 데이터 수집부터 최종 통계처리까지 걸리는 시간이 10분에서 20분까지 걸렸다.
새 NMS의 수집 플랫폼 영역엔 플럼(Flume) NG가 사용됐다. 플럼 OG에 비해 기능은 적지만 아키텍처가 단순해 여러 환경에 유연하게 적용할 수 있다는 판단에서였다.
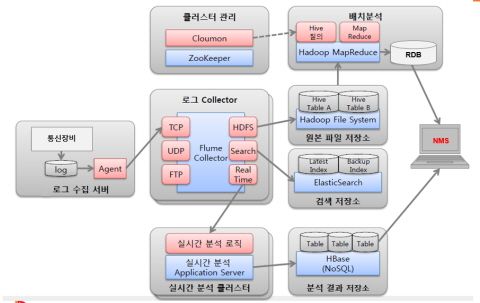
▲ SK텔레콤 NMS 플랫폼 아키텍처
홍 매니저는 “플럼은 로그 발생지에서 데이터를 백엔드로 보낼 때 부하 최소화가 매우 중요하다”라며 “배치 사이즈, 채널 버퍼 사이즈 등의 설정을 최적화하는 기본적 기능 외에 데이터가 원래 수집되는 양보다 갑자기 늘어난다거나, 데몬을 재가동하는 동안 쌓인 데이터를 한꺼번에 보내야 할 때 그를 조절하는 등의 정교한 기능은 없다”라고 말했다.
그는 “부하를 조절하는 기능을 만들어야 하며, 설치되는 시스템 스펙이나 서비스의 기본적 시스템 부하, 생성되는 로그의 양, 뒤로 보낼 수 잇는 네트워크 환경적 요소. 등에 영향을 많이 받는다는 게 플럼으로 수집환경을 구현할 때 어려운 점이었다”라고 덧붙였다.
다음은 수집된 실시간 로그 데이터를 처리하고, 저장하는 단계를 거친다. 수집된 데이터를 일단 저장했다가 분석할 때 꺼내는 방식과, 실시간 스트리밍 플랫폼에 집어넣으면서 동시에 복제본을 저장하는 분기 방식이 주로 사용된다. SK텔레콤은 분기 방식을 적용했다.
실시간으로 흐르는 데이터를 처리하는 부분은 트위터에서 개발해 공개한 ‘스톰(Storm)’이 활용됐다. 스톰은 기기에서 발생하는 이벤트를 저장과정없이 병렬처리할 수 있고, 맵리듀스와 유사한 방법론으로 데이터를 처리할 수 있으며, 하둡과 상호보완적인 역할을 수행한다. 플럼으로 수집된 데이터는 버퍼인 레디스를 거쳐 스톰으로 흘러들어간다.
홍 매니저는 “스톰은 하둡과 달리 시작은 있지만 끝은 없는, 프로세스가 항상 떠 있는 상태”라며 “하둡은 파일을 저장하면서 이름에 몇시몇분이란 시간을 붙여 구분할 수 있게 하지만, 스톰은 동시간에 여러 곳에서 들어오는 소스를 구분하는 기능을 구현해줘야 한다”라고 설명했다. 그는 “이를 위해 분산코디네이터인 주키퍼를 사용했다”라고 설명했다.
그는 “스톰 토폴로지를 구성할 때 각각의 컴포넌트를 얼마나 병렬처리를 할 건지 결정하는 게 중요하다”라며 “데이터 양이나 구현되는 로직에 성능 의존성이 큰데 정답이 없어서 계속 시도하고 문제점을 조정해가는 최적화단계가 힘들었다”라고 말했다.
그에 따르면, 스톰도 하둡처럼 특정 지점의 장애 발생 시 역할 재할당에서 발생하는 트래픽이 문제점으로 작용한다. 때문에 스톰 토폴로지는 같은 요구사항을 얼마나 단순하게 구현하느냐가 높은 성능의 관건이 된다. 그는 “요구사항 변경을 유연하게 가져가야 하고, 경험을 통해 최적화된 구성을 찾아야 한다”라고 강조했다.
플럼(수집)-버퍼(레디스)-실시간처리(스톰) 등의 순을 거쳐 나온 일분통계는 RDB에 저장되게 돼 있다. 과거 수십분이 걸리던 분단위 통계 작업시간이 획기적으로 단축돼 실시간으로 장애를 발견할 정도의 수준에 육박했다.
그러나 RDB에 저장되는 일분통계의 양이 갈수록 늘어나, SK텔레콤은 이를 NoSQL 환경으로 이전하는 작업을 진행중이다. 그리고 저장된 데이터 속에서 원인을 찾아내는 배치 분석 환경의 성능 강화를 위해 내년 1분기중 아파치 타조(Tajo)를 적용할 계획이다.
홍태희 매니저는 정확한 수치를 내보이지 않았지만, 20분까지 걸리던 일분통계가 실시간에 가깝게 이뤄지게 된 점 자체에 주목해야 한다고 강조했다.
그는 광범위한 개념으로 통용되는 빅데이터란 단어에 대한 세간의 시각을 점검하면서, 무턱대고 분석 측면이나 비즈니스 인사이트 획득에 집중하는 접근법을 에둘러 비판했다. 그는 전에 있던 문제를 해결하고 향후 더 많은 시도를 해볼 수 있는 고도화된 빅데이터 플랫폼 갖추기의 중요성을 부각시켰다.
그는 “구글이 자신들의 플랫폼을 만들 때 데이터의 의미를 찾고 분석하기 위해서 만들었다고 생각하지 않는다”라며 “수많은 사용자가 던지는 검색쿼리를 더 빠르게, 더 많이 처리하고, 관리를 자동화하기 위해 만든 분산처리기술과 플랫폼이 그 뒤의 다양한 시도로 이어졌다고 본다”라고 말했다.
현재 기업에서 쉽게 해결하지 못하는 문제점을 해소하기 위해 유연한 빅데이터 플랫폼을 구축하면, 향후 분석이나 여러 비즈니스모델 발굴 등에 접목할 수 있는 토대를 마련한다는 점에서 의미심장하다.
그는 “기존의 인프라보다 더 빠른 응답을 주고 더 많은 데이터를 수용하고 장애대응 자동화를 잘 할 수 있는 플랫폼을 보유하는 것. 그것 자체도 빅데이터에서 의미있는 부분이다”라고 강조했다.
이 같은 작업에 참여했던 홍태희 SK텔레콤 네트워크운용본부 NMC 매니저가 지난달 본지가 개최한 제10회 어드밴스드컴퓨팅컨퍼런스(ACC)에서 SK텔레콤의 네트워크관리 인프라에 적용한 빅데이터 기술을 소개했다.
SK텔레콤은 2G, WCDMA, 4G LTE, 와이브로, 와이파이 등 다양하고 복잡한 이동통신망을 운영한다. 통신품질은 사업 성패를 결정짓는 핵심 요소인 만큼 각각의 망을 관리하는 네트워크관리시스템(NMS)도 매우 중요하다.
SK텔레콤의 NMS 운영은 1초라도 빨리 장애의 원인을 찾아내는 것이 핵심이다. 통신망 장애를 정상화하는데 걸리는 시간을 얼마나 최소화하느냐가 통신사업자로서 SK텔레콤 본연의 경쟁력과 직결되는 탓이다.
SK텔레콤의 새 NMS는 각 이동통신망을 구성하는 장비에서 생성되는 로그 데이터를 수집, 처리, 저장, 분석하는 흐름으로 구성돼 있다. 홍태희 매니저가 관여한 분야는 실시간으로 로그를 수집해 분단위 통계를 내는 영역이다. 그는 하둡을 비롯한 현존하는 여러 오픈소스 기술을 이용해 SK텔레콤 NMS 요구사항에 부합하는 플랫폼을 구축했다.
일단 SK텔레콤 NMS의 최우선 전제는 데이터 수집이다. 기술적으로 각 장비에 부하를 주지 않는 방법으로 데이터를 모으고, 중간에 특정 부분의 수집작업이 끊어지지 않도록 하는 게 쉽지 않다.
기존 NMS는 장비에 대한 의존도가 컸다. 분단위 통계를 위해 데이터 수집부터 최종 통계처리까지 걸리는 시간이 10분에서 20분까지 걸렸다.
새 NMS의 수집 플랫폼 영역엔 플럼(Flume) NG가 사용됐다. 플럼 OG에 비해 기능은 적지만 아키텍처가 단순해 여러 환경에 유연하게 적용할 수 있다는 판단에서였다.
▲ SK텔레콤 NMS 플랫폼 아키텍처
홍 매니저는 “플럼은 로그 발생지에서 데이터를 백엔드로 보낼 때 부하 최소화가 매우 중요하다”라며 “배치 사이즈, 채널 버퍼 사이즈 등의 설정을 최적화하는 기본적 기능 외에 데이터가 원래 수집되는 양보다 갑자기 늘어난다거나, 데몬을 재가동하는 동안 쌓인 데이터를 한꺼번에 보내야 할 때 그를 조절하는 등의 정교한 기능은 없다”라고 말했다.
그는 “부하를 조절하는 기능을 만들어야 하며, 설치되는 시스템 스펙이나 서비스의 기본적 시스템 부하, 생성되는 로그의 양, 뒤로 보낼 수 잇는 네트워크 환경적 요소. 등에 영향을 많이 받는다는 게 플럼으로 수집환경을 구현할 때 어려운 점이었다”라고 덧붙였다.
다음은 수집된 실시간 로그 데이터를 처리하고, 저장하는 단계를 거친다. 수집된 데이터를 일단 저장했다가 분석할 때 꺼내는 방식과, 실시간 스트리밍 플랫폼에 집어넣으면서 동시에 복제본을 저장하는 분기 방식이 주로 사용된다. SK텔레콤은 분기 방식을 적용했다.
실시간으로 흐르는 데이터를 처리하는 부분은 트위터에서 개발해 공개한 ‘스톰(Storm)’이 활용됐다. 스톰은 기기에서 발생하는 이벤트를 저장과정없이 병렬처리할 수 있고, 맵리듀스와 유사한 방법론으로 데이터를 처리할 수 있으며, 하둡과 상호보완적인 역할을 수행한다. 플럼으로 수집된 데이터는 버퍼인 레디스를 거쳐 스톰으로 흘러들어간다.
홍 매니저는 “스톰은 하둡과 달리 시작은 있지만 끝은 없는, 프로세스가 항상 떠 있는 상태”라며 “하둡은 파일을 저장하면서 이름에 몇시몇분이란 시간을 붙여 구분할 수 있게 하지만, 스톰은 동시간에 여러 곳에서 들어오는 소스를 구분하는 기능을 구현해줘야 한다”라고 설명했다. 그는 “이를 위해 분산코디네이터인 주키퍼를 사용했다”라고 설명했다.
그는 “스톰 토폴로지를 구성할 때 각각의 컴포넌트를 얼마나 병렬처리를 할 건지 결정하는 게 중요하다”라며 “데이터 양이나 구현되는 로직에 성능 의존성이 큰데 정답이 없어서 계속 시도하고 문제점을 조정해가는 최적화단계가 힘들었다”라고 말했다.
그에 따르면, 스톰도 하둡처럼 특정 지점의 장애 발생 시 역할 재할당에서 발생하는 트래픽이 문제점으로 작용한다. 때문에 스톰 토폴로지는 같은 요구사항을 얼마나 단순하게 구현하느냐가 높은 성능의 관건이 된다. 그는 “요구사항 변경을 유연하게 가져가야 하고, 경험을 통해 최적화된 구성을 찾아야 한다”라고 강조했다.
플럼(수집)-버퍼(레디스)-실시간처리(스톰) 등의 순을 거쳐 나온 일분통계는 RDB에 저장되게 돼 있다. 과거 수십분이 걸리던 분단위 통계 작업시간이 획기적으로 단축돼 실시간으로 장애를 발견할 정도의 수준에 육박했다.
그러나 RDB에 저장되는 일분통계의 양이 갈수록 늘어나, SK텔레콤은 이를 NoSQL 환경으로 이전하는 작업을 진행중이다. 그리고 저장된 데이터 속에서 원인을 찾아내는 배치 분석 환경의 성능 강화를 위해 내년 1분기중 아파치 타조(Tajo)를 적용할 계획이다.
홍태희 매니저는 정확한 수치를 내보이지 않았지만, 20분까지 걸리던 일분통계가 실시간에 가깝게 이뤄지게 된 점 자체에 주목해야 한다고 강조했다.
그는 광범위한 개념으로 통용되는 빅데이터란 단어에 대한 세간의 시각을 점검하면서, 무턱대고 분석 측면이나 비즈니스 인사이트 획득에 집중하는 접근법을 에둘러 비판했다. 그는 전에 있던 문제를 해결하고 향후 더 많은 시도를 해볼 수 있는 고도화된 빅데이터 플랫폼 갖추기의 중요성을 부각시켰다.
그는 “구글이 자신들의 플랫폼을 만들 때 데이터의 의미를 찾고 분석하기 위해서 만들었다고 생각하지 않는다”라며 “수많은 사용자가 던지는 검색쿼리를 더 빠르게, 더 많이 처리하고, 관리를 자동화하기 위해 만든 분산처리기술과 플랫폼이 그 뒤의 다양한 시도로 이어졌다고 본다”라고 말했다.
현재 기업에서 쉽게 해결하지 못하는 문제점을 해소하기 위해 유연한 빅데이터 플랫폼을 구축하면, 향후 분석이나 여러 비즈니스모델 발굴 등에 접목할 수 있는 토대를 마련한다는 점에서 의미심장하다.
그는 “기존의 인프라보다 더 빠른 응답을 주고 더 많은 데이터를 수용하고 장애대응 자동화를 잘 할 수 있는 플랫폼을 보유하는 것. 그것 자체도 빅데이터에서 의미있는 부분이다”라고 강조했다.
※ 본 내용은 (주)메가뉴스(http://www.zdnet.co.kr)의 저작권 동의에 의해 공유되고 있습니다.
Copyright ⓒ 지디넷코리아. 무단전재 및 재배포 금지
[원문출처 : http://www.zdnet.co.kr/news/news_view.asp?artice_id=20131202163614]

| 번호 | 제목 | 조회수 | 작성 |
|---|---|---|---|
| 공지 | [Open UP 활용가이드] 공개SW 활용 및 개발, 창업, 교육 "Open UP을 활용하세요" | 302812 | 2020-10-27 |
| 공지 | [Open UP 소개] 공개SW 개발·공유·활용 원스톱 지원 Open UP이 함께합니다 | 293066 | 2020-10-27 |
| 2456 | [사설]한중일 기술 협력 한층 더 강화해야 | 3689 | 2013-12-04 |
| 2455 | 2013 공개 소프트웨어 개발자대회 대상에 S링크·온스퀘어 | 3258 | 2013-12-04 |
| 2454 | 제5회 공개 SW데이 상암동 누리꿈스퀘어에서 개최 | 3563 | 2013-12-04 |
| 2453 | '부드러운 변신' 소프트웨어 기반 NAS 솔루션 5종 | 4048 | 2013-12-03 |
| 2452 | 오라클 vs 구글, 12월 자바 소송 2라운드 돌입 | 3179 | 2013-12-03 |
| 2451 | IoT 뜨니 리눅스OS 노린 웜 등장 | 3001 | 2013-12-03 |
| 2450 | SKT 빅데이터 기반 NMS 뭐가 달라졌나 | 3612 | 2013-12-03 |
| 2449 | 인포뱅크, WBS 프로젝트 성과전시회에서 스마트카 기술 선봬 | 3660 | 2013-12-03 |
| 2448 | 中 짝퉁이 창의성과 결혼한다? | 3188 | 2013-12-03 |
| 2447 | OS 플랫폼, 독점과 오픈 그리고 파괴적 혁신-1 | 3479 | 2013-12-03 |
0개 댓글