


1. 기업소개
주식회사 튜닙은 자연어처리(NLP) 기반 AI 스타트업으로, 초대규모 AI 등 고난도 AI 기술을 자체 개발하고 있다. 튜닙은 한국어 챗봇 2종과 영어 챗봇 1종의 소셜 챗봇과 윤리성 판별, 비식별화 등 17가지 인공지능 API 서비스인 ‘튜니브리지(TUNiBridge)’를 선보인 바 있다.
최근에 인공지능 기술에 대한 관심이 많은데, 다가오는 메타버스 세상에서 인공지능은 중요한 역할을 할 것이고 그것이 곧 대화 기술이라 생각한다. 튜닙은 메타버스 세상 안의 콘텐츠가 될 지능을 생산하는 쪽에 집중하고 있으며 일찌감치 개발해 왔던 자연어처리와 관련된 API, 오픈소스들을 지속적으로 출시하고 본격적으로 알리는 데 집중하고 있다.
2. 튜닙 초거대 언어모델 관련 오픈소스 제품군 소개
최근 자연어처리 분야에서는 GPT3, ChatGPT 등으로 대표되는 초거대 언어 모델이 대세이다. 튜닙은 이러한 흐름에 맞추어 초거대 모델을 쉽게 학습하고, 배포하고, 사용할 수 있도록 하는 다양한 오픈소스 라이브러리 및 모델을 개발하고 제공하고 있다.
◎ OSLO (https://github.com/tunib-ai/oslo)
OSLO는 튜닙에서 개발한 초거대 언어모델 학습용 라이브러리이다. 초거대 언어모델을 학습시키기 위해서는 수많은 컴퓨팅 리소스 및 데이터가 필요하며 그들을 잘 다룰 수 있어야 한다. 그러나 이전에 이러한 경험이 부족한 개발자에게는 이들을 잘 다루는 것은 매우 어려운 일이다. OSLO는 3D 병렬화, 커널 퓨전, 데이터 메모리 매핑 등 초거대 언어모델 개발에 필수적인 고급 엔지니어링 기술들을 손쉽게 사용할 수 있도록 하며, 이로 인해 사용자는 손쉽게 초거대 언어모델을 학습할 수 있다. 현재 2.0.2 버전까지 개발되었으며 현재는 GPT-Neo를 개발한 초거대 모델 오픈소스 연구단체인 EleutherAI와 협업하여 3.0.0 버전을 개발하고 있다.
-
출처: 튜닙 GitHub
◎ Parallelformers (https://github.com/tunib-ai/parallelformers)
OSLO가 학습에 특화된 도구라면 Parallelformers는 배포에 특화된 라이브러리이다.
Parallelformers는 코드 1줄로 Huggingface Transformers에 있는 68개의 모델에 대한 inference 병렬처리를 지원하는 도구이다.
기존에 모델 추론을 위한 병렬처리 도구로 DeepSpeed-Inference 등이 있었으나, DeepSpeed-Inference은 프로세스 처리 흐름상 웹서버에 배포가 불가능하였으며, 이제는 사실상 자연어처리 도구의 표준이 된 Huggingface Transformers와의 Integration이 부족하였다. 또한 GPU 상태에서 병렬화를 시작하기 때문에 병렬화 이전에 모델의 모든 파라미터를 GPU에 올려놓아야 한다는 문제가 있었다.
하지만 Parallelformers는 DeepSpeed-Inference가 가진 여러가지 문제를 해결하였다.
초거대 언어모델은 학습하는 것도 어렵지만 이를 서비스에 배포하는 것 역시 어렵다. 초거대 언어모델을 배포하기 위해서는 메모리 용량이 큰 GPU 장치가 필요한데 이렇게 메모리 용량이 큰 GPU 장치는 사용 비용이 높다. Parallelformers는 커다란 모델을 여러 조각으로 병렬화하여 웹서버에 쉽게 배포할 수 있도록 하여 배포에 필요한 비용을 최대 3~5배까지 절감할 수 있었다.

-
출처: 튜닙 GitHub
◎ Polyglot (https://github.com/EleutherAI/polyglot)
Polyglot은 EleutherAI와 TUNiB이 함께 개발한 초거대 다국어 모델이다. Korean, Asean, Romance 등 다양한 언어군을 지원하는 다국어 모델을 개발 중이며 현재까지 Korean 1.3B, 3.8B, 5.8B 등 세 가지 모델을 출시하였다.
최근 전 세계 AI 업계에서는 파라미터(AI 연구에 쓰이는 매개변수)와 학습 데이터를 크게 늘리는 '초거대 모델'이 보편적인데, Polyglot 한국어는 58억 개 파라미터로 1.2테라바이트(TB)에 달하는 데이터를 학습한 모델이다.

-
출처: EleutherAI GitHub
3. 초거대 언어모델 대중화에 앞장선 튜닙, 오픈소스 제품 특장점 및 활용사례
초거대 언어모델은 기존 언어모델에 비해 매우 좋은 성능을 보여주지만 이를 학습시키고 사용하기 위해서는 고난도 엔지니어링 기술과 천문학적인 서버 비용이 요구된다. 먼저 튜닙의 초거대 언어모델 관련 오픈소스 제품군은 여기에 초점을 맞추었다.
현재 딥러닝 자연어처리 연구/개발에서 가장 자주 사용되는 프레임워크는 단연 Hugging Face Transformers일 것이다. OSLO와 Parallelformers 등 튜닙의 라이브러리들을 사용하기 위해서는 기존 다른 라이브러리들과 다르게 Hugging Face 기반으로 작성된 코드를 1~2줄 정도만 변화시키면 된다. 즉, 기존에 본인이 Hugging Face 라이브러리 사용에 익숙하다면 OSLO와 Parallelformers를 사용하는 방법을 미리 공부할 필요가 없다는 큰 장점이 있다.
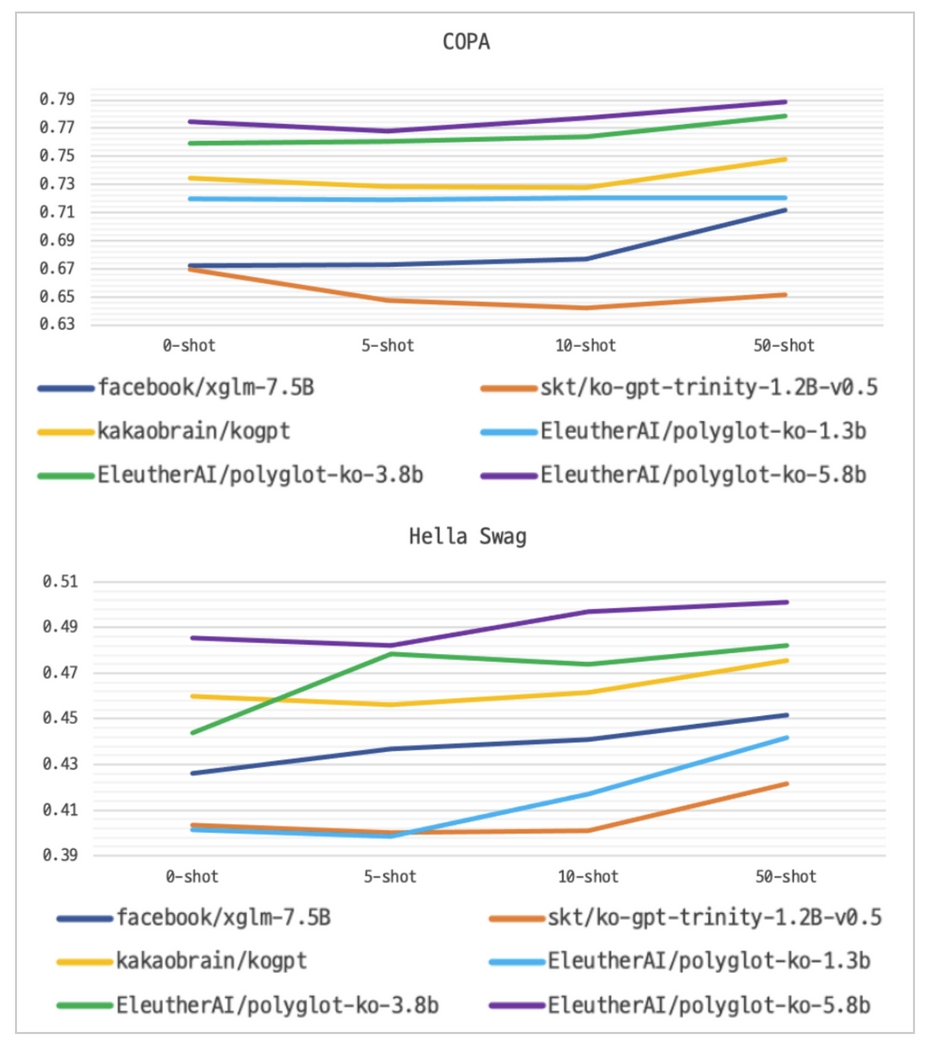
-
COPA/Hella Swag 성능 평가 그래프
출처: ElutherAI 허깅페이스 허브
Polyglot Korean 모델의 경우 기존 공개된 다른 한국어 모델들과 다르게 상업적으로 사용이 가능한 Apache 2.0 라이센스로 제공되고 있다. Polyglot Korean은 현재까지 공개된 한국어 오픈소스 언어모델 중 성능이 가장 좋은 모델 중 하나이다.
4. 맺음말
언어 기반의 초거대 모델은 챗봇, 번역 등 텍스트를 사용하는 여러 분야에서 활용된다. 다양한 오픈소스들이 공개되고 활발한 커뮤니티 활동을 통해 한국 스타트업들도 이를 무료로 사용하여 사업 아이디어를 AI로 비즈니스 할 수 있게 되었다. 튜닙은 오픈소스를 공개함으로써 AI 생태계 발전 및 확장에 기여하면서 동시에 기술력을 인정받으며 성장해가는 인공지능 대화 기술의 리더 기업으로 거듭날 것이다.

| 번호 | 제목 | 조회수 | 작성 |
|---|---|---|---|
| 344 | [오픈소스기업소개]오픈소스 APM을 활용한 서비스 성능관리 및 분석 솔인시스템 소개 | 1462 | 2023-05-25 |
| 343 | [오픈소스기업소개] 오픈소스로 만든 스마트계약 NFT 쓰리피엠 소개 | 1590 | 2023-04-24 |
| 342 | [오픈소스기업소개] 3D 프린팅 기술을 이끄는 오픈소스 기업 더블에이엠 소개 | 1426 | 2023-03-27 |
| 341 | [오픈소스기업소개] 자연어 처리(NLP)를 위한 오픈소스 튜닙 소개 | 2384 | 2023-02-20 |
| 340 | [오픈소스기업소개]바닐라브레인 | 1485 | 2023-01-20 |
| 339 | [오픈소스기업소개]스프링클라우드,로보티즈 | 1496 | 2022-12-26 |
| 338 | [오픈소스기업소개] 데이터센트릭, 마인케이 | 1434 | 2022-11-28 |
| 337 | [오픈소스기업소개] 아콘소프트, 이노그리드 | 1945 | 2022-10-25 |
| 336 | [오픈소스기업소개]인젠트,큐브리드 | 1835 | 2022-09-27 |
| 335 | [스타개발자발굴] AI 오픈소스 개발자 "조셉 폴 코헨" | 1532 | 2022-08-30 |
0개 댓글