열린마당



2015년 03월 30일 (월)
ⓒ ITWorld, Sharon Machlis | Computerworld
해마다
PDF는 기사와 책을 잘 정돈된 형식으로 보여주는 간편한 방식이다. 그러나 분석 데이터를 표현하는 데 있어서는 까다로운 부분들이
있다. 데이터베이스 또는 스프레드시트 형태로 표현해야지만 더 효과적인 확률 데이터의 경우에는 더욱 그러하다.
그렇다면 오픈소스 무료 도구인 타불라(Tabula) 를 사용해보자. PDF 파일 안에 속박된 데이터 테이블을 임의로 추출할 수
있다. 타불라는 나이트-모질라(Knight-Mozilla) 오픈뉴스(OpenNews), 뉴욕타임즈( New York Times) 와
라 나씨온(La Nación) DATA등 수많은 언론사들이 모여 만든 도구다.

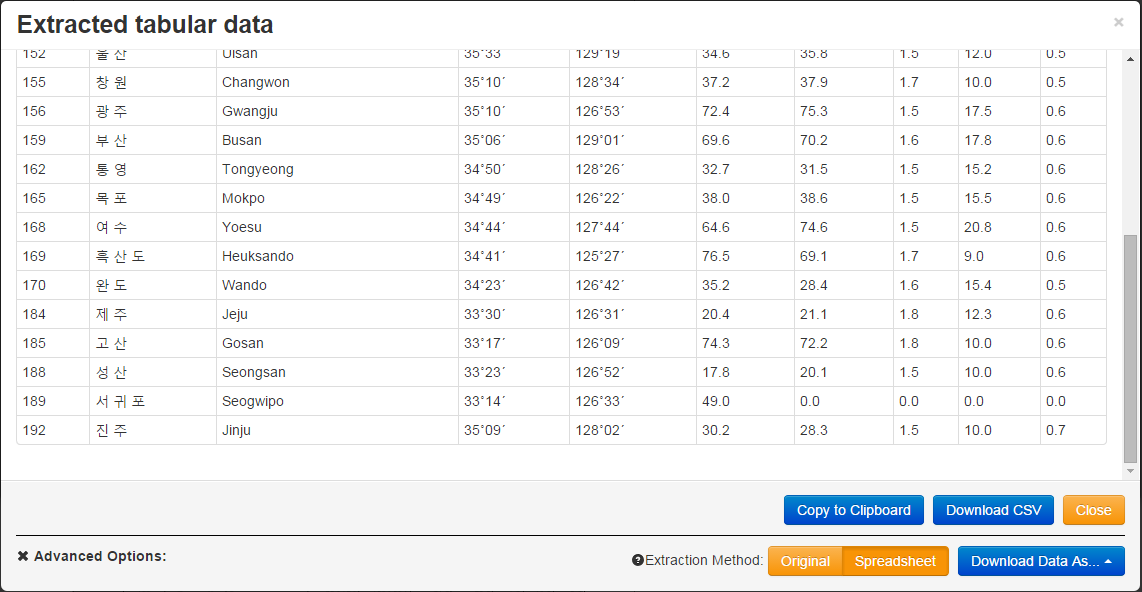
데이터를 저장하기 전에 데이터가 어떤 식으로 표현되는지 미리 확인해볼 수 있다. 어떤 영역을 선택하느냐에 따라서 열 또는 행을 놓칠 공산이 있기 때문이다.
타불라 프로젝트에서 제작한 30초 비디오를 보면 윈도우에서 어떻게 동작하는지를 확인해볼 수 있다. OS X와 리눅스 버전의 타불라도 이용할 수 있다.
타불라는 편집 가능한 텍스트 형태의 PDF에서만 테이블 데이터를 추출할 수 있으며, OCR 소프트웨어가 아니므로 스캔된
이미지에서는 동작하지 않는다. 또 한가지 주의할 것은 간단한 형태의 테이블에서 가장 잘 동작하며, 한 셀에 여러 행 또는 열이
존재할 경우에는 제대로 동작하지 않을 수 있다는 점을 주의해야 한다.
※ 본 내용은 한국IDG(주)(http://www.itworld.co.kr)의 저작권 동의에 의해 공유되고 있습니다.
Copyright ⓒITWORLD. 무단전재 및 재배포 금지
[원문출처 : http://www.itworld.co.kr/news/92615]

| 번호 | 제목 | 조회수 | 작성 |
|---|---|---|---|
| 공지 | [Open UP 활용가이드] 공개SW 활용 및 개발, 창업, 교육 "Open UP을 활용하세요" | 295871 | 2020-10-27 |
| 공지 | [Open UP 소개] 공개SW 개발·공유·활용 원스톱 지원 Open UP이 함께합니다 | 286335 | 2020-10-27 |
| 4037 | [오픈소스의 힘] ⑤오픈소스, 네트워크를 제어하다 | 3195 | 2015-04-02 |
| 4036 | 본엔젤스, 모바일 지도 개발사 다비오에 10억원 투자 | 3218 | 2015-04-02 |
| 4035 | 샤오미, 마침내 Mi3, Mi4, Mi Note의 커널 소스파일 공개 | 3722 | 2015-04-02 |
| 4034 | 미래부-서울시, 공공IoT 해커톤 연다 | 3350 | 2015-04-02 |
| 4033 | 상업용 오픈소스 프로젝트의 명과 암 | 3567 | 2015-04-02 |
| 4032 | 샤오미 '오픈소스 공개 위반' 해외시장 진출 길 막혔다 | 3350 | 2015-04-02 |
| 4031 | 공개SW, 테스팅을 만나다 | 3363 | 2015-04-02 |
| 4030 | 오픈소스SW 사이트 '기트허브', DDoS 공격에 마비 | 2990 | 2015-04-02 |
| 4029 | PDF에서 테이블 데이터 추출하기 : 타불라 | 4283 | 2015-03-30 |
| 4028 | [주간 클라우드 동향] 클라우드 왕좌는 누가?…법 시행 전 선결과제도 산적 | 3749 | 2015-03-30 |
0개 댓글