


글 : 김진철 | CIO KR / 2018.03.23
LCG 데이터 병렬 처리 프레임워크 - PROOF
본 연재의 여섯 번째 글에서 잠시 소개했던 LHC 이벤트 데이터를 분석 과정을 잠시 되새겨 보기로 하자. LHC 이벤트 데이터 분석 과정은 먼저 검출기의 Level-1 트리거와 고수준 트리거(high-level trigger)에서 수행되는 이벤트 데이터 파편(fragment)들을 검출기 센서의 위치에 맞게 배치, 병합하고, 물리학자들이 물리학적인 분석이 가능하도록 기초적인 메타데이터를 추가하는 자동화된 데이터 분석 과정이었다. 이렇게 자동화된 데이터 분석 과정은 물리학자들이 힉스 보존과 같은 새로운 입자를 쉽게 찾게 해주거나, 입자의 특성을 더 정밀하게 분석하길 원하는 입자에서 필요한 정보를 쉽게 계산해낼 수 있도록 이벤트 데이터를 가공하는 과정이다.
위와 같이 검출기의 온라인 데이터 수집 시스템을 통해서 이벤트 데이터를 자동으로 가공한 후에는 물리학적인 분석을 위한 단계에 들어간다. 이런 추가의 물리학적인 정밀한 분석이 필요한 이유는 자동화된 분석 단계에서 쓰이는 인공지능 기술이 아직 물리학자들이 물리학적 분석을 하는 것과 같이 복잡하고 창조적인 작업을 할 수 있을 정도로 발전하지 않았기 때문이다. 현재 LHC 이벤트 데이터 분석 과정에서 자동화된 부분은 앞서 여섯 번째 글에서 소개한 바와 같이 시뮬레이션을 통해 생성된 이벤트 데이터와 실제 수집된 이벤트 데이터를 비교하여 원시 이벤트 데이터에 시뮬레이션 데이터에서 추정된 메타데이터를 덧붙이는 패턴 매칭 과정이라고 소개한 바 있다.
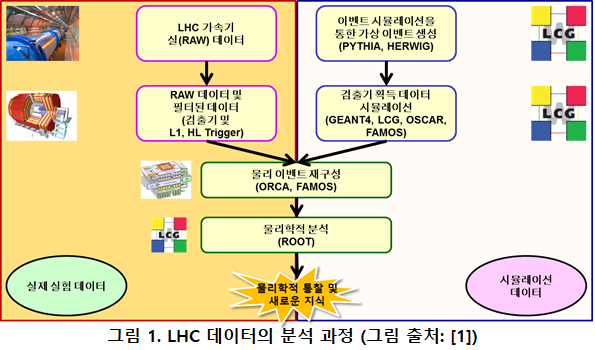
CMS를 비롯한 LHC의 각 검출기들이 초당 4천만 번의 횟수로 일어나는 양성자 빔 충돌로 인해 Level-1 트리거를 거치기 전에는 1TB이상의 많은 원시 데이터를 쏟아내지만, 양성자 빔 충돌 한번의 이벤트 데이터는 2MB 정도로 그렇게 큰 편이 아니다. 각각의 양성자 빔 충돌 이벤트는 서로 상호 연관이 없는 통계적으로 독립적인 이벤트들로 볼 수 있기 때문에 각 이벤트 데이터를 개별적으로 분석해도 문제가 없다. 이렇게 통계적으로 독립적인 작은 크기의 이벤트 데이터가 많은 수로 쏟아지는 형태로 데이터가 생성되기 때문에 고처리량 연산(high-throughput computing) 형태의 작업으로 분석할 수 있게 된다.
고처리량 연산(high-throughput computing) 컴퓨팅 형태의 작업은 개별 작업에서 다루는 데이터의 양은 하나의 서버나 노드에서 계산할 수 있을 만큼 작지만, 이런 개별 작업으로 다루어야 하는 데이터의 수가 매우 많아서 병렬 연산이 필요한 형태의 고성능 컴퓨팅 작업이다. 고처리량 컴퓨팅 작업과 반대되는 완전 병렬 연산(fully-parallel computing)이 필요한 작업은 데이터 자체도 하나의 서버나 노드에서 처리할 수 없을 만큼 커서 한번의 계산을 위한 데이터를 여러 대의 노드에 나누고, 여러 대의 노드에 나누어진 데이터 간에 병렬, 분산 컴퓨팅 알고리즘을 이용해 큰 계산을 수행하는 것이다.
LHC 물리학자들이 많은 수의 이벤트 데이터를 분석하려면 고처리량 연산을 손쉽게 할 수 있는 병렬 연산 소프트웨어 도구가 필요했다. 전 지구적인 슈퍼컴퓨팅 인프라인 LHC 컴퓨팅 그리드(LHC Computing Grid; LCG)에서는 많은 연산을 손쉽게 병렬로 처리할 수 있도록 Condor, OpenPBS, Platform LSF, Torque 등 당시에 고처리량 병렬 연산을 위해 개발된 작업 스케줄러들을 LCG 그리드 미들웨어가 그리드 자원 관리 기능과 연계해서 통합, 지원하였다.
당시 LCG에서 쓰였던 이런 작업 스케줄러들은 오늘날의 하둡과 같은 프레임워크의 형태가 아니었다. 프로세스 단위의 실행 파일, 실행에 필요한 관련 파일과 데이터를 하나의 샌드박스 형태로 만들고 실행할 파일을 실행하는 방법과 내용을 입력 파일 스크립트(input file) 형태로 간단하게 기술하여 쉘 프롬프트에서 작업 스케줄러 명령에 입력 파일과 샌드박스에 대한 정보를 넘기는 식으로 실행하였다.
이렇게 LCG에서 쓰였던 작업 스케줄러들은 프로세스 단위로 병렬화할 수밖에 없었기 때문에 병렬 계산을 하는 작업과 전체 분석 작업이 유기적으로 통합되지 못하고 분리되어, 작업 실행이 스케줄러의 큐(queue)에 들어온 순서대로 순차적으로 실행될 수밖에 없었다. 작업이 실행되는 동안에는 작업 내용에 대한 피드백을 받기가 어려웠고, 가장 마지막 서브작업이 끝나야 전체 작업이 끝났기 때문에 데이터 분석에 많은 시간이 소요되고 융통성을 발휘하기 어려웠다. 이런 이유로 작업 스케줄러를 이용한 이벤트 데이터 작업 병렬화는 데이터 분석 실행과정 자동화와 복잡한 빅데이터 처리 워크플로우 실행에는 한계가 있었다.
CERN에서는 LHC를 건설하기 전에 전자빔과 양전자빔을 충돌시켜 입자물리학 현상을 조사하였던 LEP(Large Electron-Positron Collider) 가속기 시절부터 PAW와 PIAF 등의 데이터 분석 소프트웨어를 만드는데 많은 노력을 기울였다. 1995년 CERN의 SPS 가속기에서 중이온 빔실험을 하던 르네 브룬(Rene Brun)과 CERN 내 휴렛패커드의 리눅스 에반겔리스트로 일하던 폰즈 라드메이커스(Fons Rademakers)가 실험 장치의 데이터 수집과정 조작(manipulation), 제어부터 고급 입자 물리학 분석에 이르는 이벤트 데이터 분석의 전 과정을 하나의 분석 환경에서 편리하게 수행할 수 있게 하려고 ROOT라고 하는 분석 소프트웨어를 만들기 시작하였다.
당시 물리학자들이 LEP나 LHC와 같은 복잡한 실험 장치를 제작, 제어하고 이벤트 시뮬레이션과 분석을 위한 복잡한 계산을 하는 과정에서 대부분 C/C++ 언어를 사용하였기 때문에, ROOT의 분석 로직을 표현하는 기본 언어도 C/C++를 사용하여 만들어졌다. 다만, R이나 MATLAB, OCTAVE와 같이 명령행 환경에서 대화식 분석이 가능하도록 C/C++ 인터프리터인 CINT를 기반으로 대화식 분석을 할 수 있도록 하였다.
LHC 가속기 건설 막바지에 다른 2003년경부터는 물리학자들이 수행하는 이벤트 분석 내용이 대부분 ROOT를 통해서 작성되고 있었기 때문에, 작업 스케줄러를 통해 여러 노드에 작업을 분산하고 그 결과를 돌려받아 후속 연산이나 작업을 하는 과정을 프로그램하는 것도 ROOT의 기반 언어인 C/C++로 작성될 수 있어야 했다.
LCG 그리드 미들웨어가 개발되던 당시에는 Condor나 Torque 등의 작업 스케줄러에서 제공되는 API가 없거나 있더라도 오늘날의 하둡과 같은 추상화된 프로그래밍 모델을 통해 제공되는 것이 아니어서 응용 프로그램과 통합이 쉽지 않았다. Open Grid Forum과 같은 오픈 소스 그리드 컴퓨팅 단체를 통해서 제정된 작업 관리 및 기술(description)에 대한 표준인 JSDL(Job Submission and Description Language)나 DRMAA(Distributed Resource Management Application API; DRMAA)와 같은 작업 및 자원 관리 메시지 표준이 제정되어 이를 작업 스케줄러에서 지원하게 된 것은 꽤 시간이 지난 후의 일이었다. JSDL이나 DRMAA를 통해 작업 스케줄러를 제어하고 상호작용 하는 방법이 여러 프로그래밍 언어 환경에서 단일화된 메시지 기반 인터페이스를 제공한다는 점에서는 바람직했지만, 개발자들이 직접 JSDL이나 DRMAA를 다루는 것은 번거로운 일이었다.
---------------------------------------------------------------
김진철 칼럼 인기기사
-> 김진철의 How-to-Big Data | 연재를 시작하며
-> 김진철의 How-to-Big Data | 빅데이터 활용의 근본적인 질문 - 해결하려는 문제가 무엇인가?
-> 김진철의 How-to-Big Data | 빅데이터 수집에 관한 생각 (1)
-> 김진철의 How-to-Big Data | 빅데이터 수집에 관한 생각 (2)
-> 김진철의 How-to-Big Data | 빅데이터 수집에 관한 생각 (3)
---------------------------------------------------------------
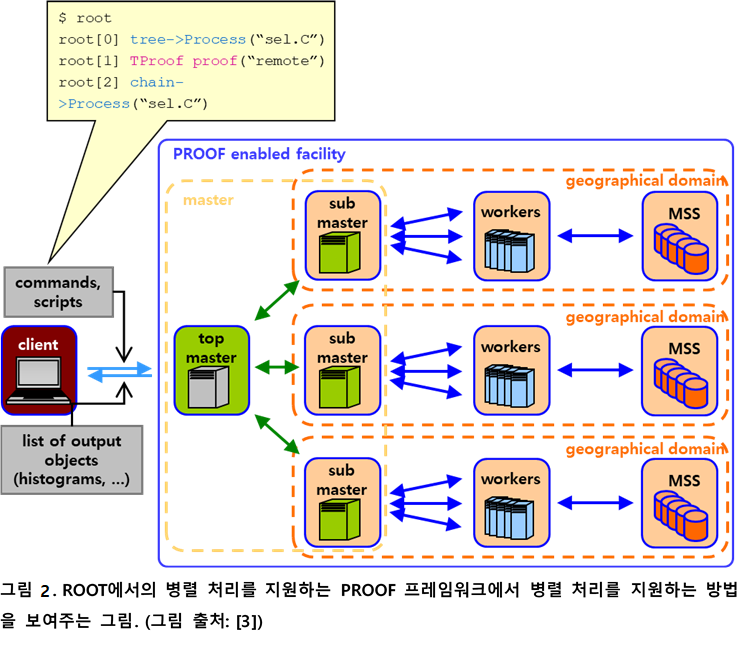
위와 같은 이유로 고처리량 연산을 ROOT에서 지원하기 위한 PROOF(Parallel ROOT Facility; PROOF)라는 C/C++언어 기반의 병렬 처리 프레임워크가 CERN의 ROOT 핵심 개발자들인 르네 브룬(Rene Brun)과 폰즈 라드메이커스(Fons Rademakers), MIT의 중이온 물리 연구실(Heavy Ion Group)의 마틴 발린틴(Maarten Ballintijn), 군터 롤랜드(Gunther Roland), 크리스 굴브란드슨(Kris Gulbrandsen)에 의해 개발되었다. PROOF는 ROOT의 C++ API 형태로 제공되며, 작업을 실행할 워커(worker) 노드의 정보와 작업을 분배할 내용을 C++ API를 이용해 기술해주면 ROOT C++ 분석 코드 안에서 병렬 처리를 위한 과정을 모두 제어할 수 있어서 LHC 데이터 분석의 생산성을 크게 높여주었다.
PROOF는 마스터-슬레이브 형태로 클러스터를 조직해서 작업을 병렬화하게 되며(그림 2), 마스터 노드는 여러 계층으로 계층화해서 여러 LCG Tier-1, Tier-2, Tier-3 데이터 분석 자원에 이르는 계산 자원을 통합하여 병렬 연산을 할 수 있게 한다. 실제 계산이 수행되는 워커 노드는 PROOF에서 하둡의 HDFS와 유사한 역할을 하는 병렬 파일 시스템인 SCALLA나 그리드 스토리지 시스템에 저장된 데이터에 접근해서 PROOF를 사용해 작업을 병렬화한 소스코드에 기술되어 있는 대로 작업을 병렬화하여 실행한다.
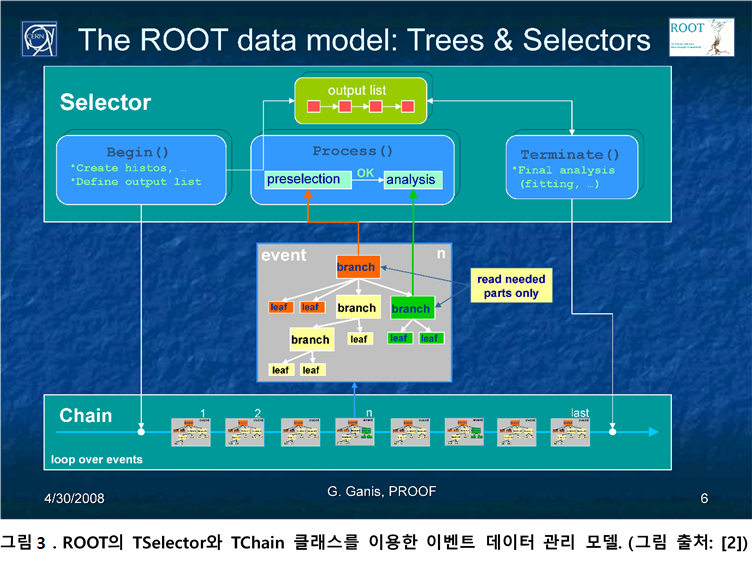
초기 버전의 PROOF에서는 ROOT의 대용량 데이터 접근 클래스인 TTree와 TChain을 이용해서 데이터 병렬(data-parallel) 방식의 병렬처리 방법을 기술하였다. ROOT의 TSelector 클래스를 이용하면 Condor, OpenPBS의 작업 기술(job description) 입력 파일(input file) 형식으로 ROOT 스크립트 외부에서 작업 병렬화를 기술하는 것이 아니라, ROOT 스크립트 내부에서 ROOT 스크립트 단위로 작업 병렬화를 기술할 수 있어 병렬화된 작업을 관리하는 것이 Condor나 OpenPBS 등의 작업 스케줄러보다 한층 일관되고 수월하다([3], 그림 2, 3).
최근 버전의 ROOT와 PROOF에서는 TExecutor 인터페이스를 만족하는 TProcessExecutor, TThreadExecutor 클래스를 이용해 병렬화할 수 있다. 이들 TProcessExecutor, TThreadExecutor 클래스는 하둡 스타일의 맵리듀스 프로그래밍 패턴도 지원한다. 최근 버전의 ROOT와 PROOF에서 지원되는 ROOT:EnableImplicitMT 함수를 이용하면 순차적인 로직을 가지는 ROOT 분석 스크립트를 자동으로 병렬화할 수도 있다[4].
요즘 많이 쓰이는 하둡이 유명해진 이유 중 하나가 데이터 블록 단위의 데이터 지역성(data locality)을 지원하는 것이다. 계산하는 작업이 계산에 필요한 해당 데이터 블록이 있는 노드에서 실행되는, 데이터 지역성을 고려한 작업 스케줄링의 개념이 바로 PROOF에서 지원되었다. PROOF에서는 데이터 뭉치 단위가 아닌 이벤트 데이터 파일 단위의 데이터 지역성(data locality)을 지원한다. 그렇지만, 하둡에서도 데이터 블록은 역시 파일 단위로 저장되기 때문에 PROOF의 데이터 지역성의 개념은 하둡의 데이터 지역성의 조상이라고도 볼 수 있다.
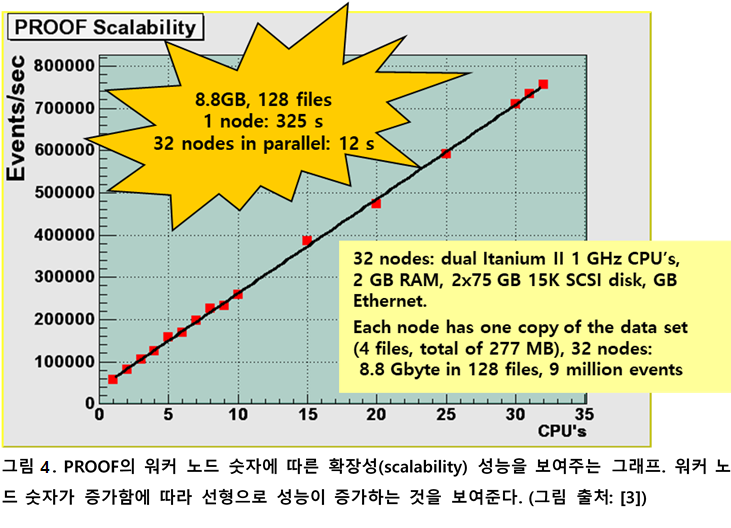
독자들도 잘 아시겠지만, 하둡의 작업 스케줄러는 특정 워커 노드에서 실행되는 맵이나 리듀스 작업 실행이 실패하면 자동으로 해당 작업만을 다시 실행하는 결함 포용 작업 실행(fault-tolerant job execution)을 지원한다. PROOF는 하둡과 같은 결함 포용 작업 관리(fault-tolerant job management)를 하지 않아서 워커에서 실행되는 작업이 죽으면 전체 작업이 중단된다. PROOF가 하둡과 같은 결함 포용 작업 관리를 하지는 않았지만, 각 서브작업 단위로 실시간으로 작업 상태와 내용에 대한 피드백을 제공하기 때문에 Condor나 OpenPBS 등의 작업 스케줄러에 비해서는 작업 실행의 속도와 성공률을 많이 높일 수 있었다.
하둡의 분산파일 시스템인 HDFS에서는 데이터 블록 복제(replication) 기능을 통해 데이터의 안정성을 높이지만, PROOF는 이런 데이터 복제 기능이 없다. 하둡의 HDFS는 같은 데이터 블록을 여러 개, 보통은 3개를 복제하여 다른 노드에 위치하게 하여, 특정 데이터 블록이 데이터를 저장하는 디스크나 서버의 문제로 유실되더라도 다른 복제본으로 데이터 유실을 방지하여 데이터 저장 및 관리의 신뢰성을 높인다.
하둡의 선형 확장성이 PROOF보다 좋지 않지만[5], 하둡의 데이터 지역성(data locality)을 고려한 계산과 결함 포용 작업 관리, 데이터 복제를 통한 데이터의 신뢰성 향상 등은 분명히 PROOF대비 하둡의 장점이기 때문에 최근에는 하둡을 이용한 LHC 데이터 분석 사례도 늘어나고 있다. 최근 ROOT에서 하둡이나 스파크 등의 빅데이터 기술을 이용한 병렬 연산을 지원하기 위한 연구를 고에너지 물리학자들이 연구하고 있다[6].
하둡이나 스파크와 같은 빅데이터 기술이 등장하기 전까지 PROOF는 LHC 연구자들에게 LHC 빅데이터를 분석하는 데 필요했던 병렬 연산을 손쉽게 제공해주었던 중요한 도구였다. 당시에 Condor, OpenPBS, Torque 등의 작업 스케줄러에는 없었던 고처리량 연산(high-throughput computing)을 위한 추상화된 프로그래밍 모델과 API를 제공하였다. 이 때문에 ROOT를 이용해 LHC 빅데이터를 분석했던 LHC 물리학자들이 병렬 컴퓨팅에 대한 전문적인 지식이 없이도 손쉽게 LCG 그리드 자원을 이용한 대규모 빅데이터 분석을 할 수 있었다.
비록 PROOF에서 하둡과 같은 데이터 복제 기능과 결함 포용 작업 관리(fault-tolerant job management)는 지원하지 않았지만, 하둡에서 지원되는 랙 단위 자원 인식과 이를 이용해 데이터와 작업을 스케줄링하는 랙 인식 작업 스케줄링(rack-aware job scheduling)과 함께 전 지구적인 그리드 자원의 계층과 서비스 지역을 인식해서 작업을 스케줄링할 수 있는 훨씬 큰 규모의 자원 계층 인식 스케줄링(resource hierarchy-aware scheduling)이 가능했다. 하둡이 나타나기 훨씬 전부터 빅데이터를 위한 프로그래밍 모델과 자원 관리 모델을 제시하고 빅데이터 분석을 실현했다는 점에서 PROOF는 구글의 맵리듀스나 하둡, 스파크만큼이나 빅데이터 기술 역사에 기록될 만한 소프트웨어 도구이다.
빅데이터 문제 해결의 기본적인 도구 – 병렬 처리 프레임워크
하둡은 최근 IT 산업계에서의 빅데이터 붐을 일으킨 장본인으로서 아직도 그 인기는 여전하다. 스파크가 크게 주목받으면서 상대적으로 덜 언급되기는 하지만, 그래도 데이터 기반 비즈니스에서 빅데이터를 처리한다고 하면 우선 하둡을 떠올리게 할 정도로 최근 빅데이터 붐을 이끌어온 기술이다.
한 대의 서버로 처리하기 어려운 빅데이터를 처리하기 위해서는 여러 대의 서버에 데이터 처리를 분산해서 많은 데이터를 처리하게 하는 빅데이터 병렬 처리 프레임워크는 필수적이다. 이 때문에 오픈 소스 소프트웨어로 접근이 쉽고, 맵과 리듀스 패턴으로 데이터 병렬 처리를 단순화하여 병렬 처리 알고리즘 개발을 쉽게 한 하둡은 빅데이터 활용이 확산되도록 IT 산업계에 큰 공헌을 한 기술임은 누구도 부인할 수 없을 것이다.
다만 필자가 지금까지 여러 번 언급했듯이, 빅데이터 비즈니스의 모든 문제가 하둡과 같은 빅데이터 기술만 잘 활용하면 해결된다는 식으로 IT 업계 분위기가 한동안 흘러갔던 것은 이제 좀 바뀌어야 하지 않을까 싶다. 다행히도 최근에는 데이터 기반 비즈니스의 성공 사례가 국내외에서 점점 늘어나고 있고, 빅데이터를 위한 다양한 기술들이 등장하고 적용되면서 하나의 빅데이터 기술이 빅데이터 비즈니스의 모든 것을 해결한다는 인식은 점점 사라지고 있는 듯하다.
CERN에서도 LHC 빅데이터를 처리하기 위해 병렬 처리를 위한 기술은 필수적으로 확보해야 했다. LHC를 건설하던 당시 병렬 처리나 고성능 컴퓨팅의 대부분은 물리학이나 화학, 엔지니어링 및 공학 분야에서 편미분 방정식의 해를 찾거나 시뮬레이션을 위한 병렬 계산이 대부분이었다. 병렬 처리 기술 대부분이 이런 병렬 계산을 위한 MPI(Message Passing Interface) 기반의 메시지 기반 병렬 처리 연산의 속도를 높이는 데에 초점이 맞추어져 있었다. LHC 빅데이터의 워크로드 패턴이 비즈니스 빅데이터 워크로드 패턴과 유사한 고처리량 연산 형태인 것, LHC 건설 초반에 많은 관심을 받았던 그리드 컴퓨팅 기술 초기에 고처리량 연산 형태의 워크로드를 위한 작업 스케줄러 기술이 많이 개발되었던 것은 LHC 실험 연구자들에게는 행운이었다.
빅데이터 처리가 복잡하고 어려우며 문제에 따라서 다양한 해결 방법이 있을 수 있겠지만, 비즈니스 빅데이터 처리를 위한 워크로드 패턴은 많이 쓰이는 몇 가지의 패턴으로 정리될 수 있다. 이런 워크로드 패턴들을 이용해 빅데이터 처리 논리 개발을 단순화하고, 데이터 과학자나 빅데이터 응용 프로그램을 개발하는 소프트웨어 엔지니어들이 비즈니스 고유의 요구사항에 집중할 수 있게 해주는 빅데이터 병렬, 분산 처리 프로그래밍 모델과 이를 구현한 프레임워크는 빅데이터의 모든 것이 아닐지라도 분명 중요한 기술 요소다.
지난 열 세번째 글에서도 잠시 언급했던 아파치 HAMA 등에서 맵리듀스 프로그래밍 모델을 좀더 일반화한 Bulk Synchronous Parallel(BSP) 모델, 최근 딥러닝 프레임워크로 각광받고 있는 텐서플로(TensorFlow)에서 사용하고 있는 데이터 플로우 모델(Dataflow programming model) 등의 프로그래밍 모델이 최근 많이 연구되면서 소프트웨어 엔지니어들이 활용할 수 있는 빅데이터 프로그래밍 모델과 이를 지원하는 소프트웨어 기술이 점점 많아지고 있어 해결할 수 있는 빅데이터 비즈니스 문제의 범위가 점점 넓어지고 있다. 이렇게 빅데이터 기술의 발전으로 해결할 수 있는 비즈니스 문제의 범위가 넓어지는 것은 분명 새로운 비즈니스 기회로 이어질 수 있다.
빅데이터 처리를 위해 병렬, 분산 처리 기술을 활용하면서 다음의 네 가지를 꼭 기억하자.
첫 번째로, 거듭 강조하는 것이지만, 비즈니스의 목표에 부합하고, 빅데이터를 이용한 비즈니스의 문제를 해결하는데 적합한 빅데이터 병렬, 분산 처리 기술을 선별해서 사용해야 한다.
하둡이나 스파크가 분명히 좋은 병렬, 분산 처리 기술이지만, 분명히 두 기술 모두 나름의 특성이 있고 한계를 가지고 있다. 하둡은 많은 데이터를 디스크와 같은 영속저장장치(persistent storage)에 두고 병렬, 분산화된 작업이 서로 독립적으로 실행될 수 있는 빅데이터 처리에 적합하다. 하둡의 특성상 디스크 I/O가 많으면 성능이 떨어지게 마련이라 스파크를 같이 활용하는 경우가 많다.
스파크의 경우는 인메모리 빅데이터 처리 기술이기 때문에 저지연(low latency) 데이터 처리가 가능하지만 반대로 한번에 처리할 수 있는 데이터의 양이 메모리 용량에 좀더 제약을 받을 수밖에 없고, 스칼라 언어를 기반으로 하고 있다는 것을 고려해서 도입을 고려해야 할 것이다.
특히 스파크의 경우 하둡과 같이 쓰게 되는 경우가 많은데, 스파크가 기반을 둔 스칼라가 자바 가상 머신에 기반을 둔 언어이기 때문에 이런 사용 방법이 상대적으로 쉬운 것이지, Java가 아닌 다른 프로그래밍 언어를 비즈니스 IT 시스템의 기반 플랫폼으로 사용하고 있는 조직에서는 스파크를 도입하기 전에 좀더 신중하게 검토할 필요가 있다. 서로 다른 프로그래밍 언어를 사용하는 이종 개발 환경에서의 비즈니스 시스템 개발, 관리 과정에서 올 수 있는 문제와, 스칼라 언어 자체가 복잡하고 어렵기 때문에 스칼라 언어의 특성을 최대한으로 활용할 수 있도록 소프트웨어 엔지니어들을 훈련시키는데 생각보다 많은 노력이 들 수 있다는 점을 고려할 필요가 있다.
다행히도 요즘은 이런 이종 프로그래밍 언어를 사용하면서 오는 문제는 거의 없는 편이다. 하둡과 스파크도 Java와 스칼라외의 Python과 같은 다른 언어로의 인터페이스를 제공하는 라이브러리들이 많이 개발, 공개되어서 요즘은 서로 다른 프로그래밍 언어를 써서 빅데이터 비즈니스 시스템을 개발하는 문제는 생각보다 장벽이 높지 않다. 이런 최근의 경향 때문에 C++기반의 분석 플랫폼인 ROOT를 주로 쓰는 CERN에서도 하둡과 스파크를 적극적으로 활용하려 한다.
하둡과 스파크가 해결할 수 있는 문제의 범위는 넓은 편이다. 그렇지만, 빅데이터 비즈니스의 모든 기술적인 문제를 해결할 수 있는 것은 아니다. 빅데이터 비즈니스를 위한 IT 시스템은 하둡, 스파크 시스템을 포함한 전체 데이터 처리 파이프라인을 위한 시스템으로 구성해야 한다는 사실을 잊지 않도록 하자.
두 번째로, 빅데이터 분석 플랫폼과의 통합이 용이해야 한다. 분석 플랫폼에서 병렬, 분산 처리 기술을 위한 인터페이스가 제공되는지, 만약 제공되지 않는다면 빅데이터 분석 소프트웨어가 분석 데이터 가공을 위한 병렬, 분산 처리 과정이 쉽게 분석 로직과 통합이 될 수 있을지 신중하게 검토되어야 한다.
데이터과학팀에 빅데이터 병렬, 분산 처리 기술을 포함한 빅데이터 관련 IT 기술에 상당히 밝은 데이터과학자가 많아서 빅데이터 가공, 분석, 해석까지 직접 설계, 수행할 수 있다면 문제가 없겠지만, 빅데이터 가공을 전담하는 데이터 엔지니어와 빅데이터 분석과 해석을 담당하는 데이터분석가가 나뉘어 있는 데이터과학팀의 경우에는 빅데이터 분석 플랫폼에서 간편하게 빅데이터 병렬, 분산 처리를 할 수 있는지가 팀의 개발, 분석 속도와 생산성에 크게 영향을 줄 수 있다. CERN의 경우, PROOF를 통해 ROOT에서 병렬, 분산 처리를 쉽게 할 수 없었다면 LHC 데이터 분석을 통해 힉스 입자를 발견하는데 더 많은 시간이 걸렸을 가능성이 높다. LHC 실험의 데이터과학자인 입자물리학자들이 상대적으로 다른 과학 분야에 비해 IT 기술에 밝기는 하지만, 그래도 병렬, 분산 처리를 깊게 알고 능숙하게 다룰 수 있는 사람은 적기 때문에 ROOT상에서 PROOF를 통한 병렬 처리를 쉽게 할 수 있었다는 것은 큰 장점이었다.
세 번째로, 빅데이터 병렬, 분산 처리 소프트웨어와 인프라에서 데이터 소스에의 접근과 활용이 용이해야 한다. 이는 빅데이터 병렬, 분산 처리 기술이 쓰이는 주된 용도가 빅데이터를 가공해서 원하는 정보만을 추출하고 분석에 필요한 데이터의 양을 줄이는데 많이 쓰이기 때문이다.
빅데이터를 처리하기 위한 병렬, 분산 처리 소프트웨어가 원시 빅데이터에 쉽게 접근하여 원하는 데이터를 얻지 못한다면 아무리 빠르게 병렬, 분산 처리를 할 수 있다고 해도 빅데이터 처리 자체가 매우 어려워질 것이다.
원시 빅데이터 접근을 용이하게 하는 것은 단순히 병렬, 분산 처리 소프트웨어에서 다양한 종류의 원시 빅데이터에의 접근을 위한 API를 제공하는 것만의 문제가 아니다. 원시 빅데이터에 접근하여 원하는 데이터만을 선별하는데 많은 시간이 걸리거나, 원하는 데이터만을 골라 필요한 위치로 전송하고 옮기는데 많은 지연이 생기지 않도록 빅데이터 인프라내의 네트워크가 적절하게 디자인되고 관리되는 문제도 포함한다. 원시 빅데이터 접근을 고려하여 빅데이터 인프라의 네트워크와 테크니컬 아키텍처가 디자인되어야 빅데이터 처리와 분석 과정에서의 병렬, 분산 처리 소프트웨어의 역할이 더욱 빛날 수 있다.
네 번째로, 빅데이터 가공, 분석 과정을 하나의 전체 파이프라인으로 구성, 관리할 수 있게 해주는 워크플로우와 오케스트레이션 관리 도구가 있고, 이런 워크플로우와 오케스트레이션 도구를 통해 빅데이터 병렬, 분산 처리 과정이 통합되는 것이 바람직하다.
이후 연재에서 좀더 자세하게 소개하겠지만, CERN의 LCG에서는 그리드 워크플로우 기술이 개발되어 쓰였다. 이런 그리드 워크플로우 기술은 그리드 자원에서의 정보처리 과정이 그리드 자원 관리와 연계되어 적절한 자원에 스케줄링되어 실행될 수 있도록 체계적으로 관리하게 된다. 이렇게 그리드 워크플로우 기술과 통합된 병렬, 분산 처리 과정은 빅데이터 인프라 자원을 사용성을 높이는 데에도 도움이 되지만, 데이터 가공 및 분석 전체 과정을 조망하면서 데이터 가공, 처리를 할 수 있도록 데이터 엔지니어를 돕기 때문에 복잡한 빅데이터 처리 개발 과정의 생산성을 높일 수 있다.
워크플로우 형태로 표현된 빅데이터 프로세스는 데이터 엔지니어, 도메인 전문가, 데이터과학자가 팀을 이룬 데이터과학팀에서 빅데이터 분석 협업과 프로세스 통합, 조율을 용이하게 할 수 있다. 대개의 경우 데이터과학자가 빅데이터 분석에 필요한 모든 업무와 기술을 소화하기는 쉽지 않기 때문에 팀 단위의 협업을 할 수밖에 없는데, 팀 단위의 협업을 구체적이고 명료한 업무로 만드는데 워크플로우와 오케스트레이션 기술은 효과적으로 활용된다.
빅데이터 처리 프로세스를 위한 워크플로우와 오케스트레이션 도구는 데이터 수집, 가공, 분석 전 과정을 하나의 프로세스 단위로 묶어 주기 때문에 데이터 소스 접근부터 빅데이터 병렬, 분산 처리까지 전 프로세스의 디자인과 구현이 신속하고 정확하게 이루어질 수 있다. 보통 이런 워크플로우는 그림과 도형으로 표현이 되는 GUI 형태로 만드는데, 이렇게 GUI로 도식적으로 표현된 워크플로우는 데이터과학팀 모두가 만들어야 하는 데이터 가공 및 분석 과정에 대한 명료한 비전과 목표를 워크플로우 단위로 제시할 수 있게 한다. 빅데이터 워크플로우는 빅데이터 가공, 분석 과정을 자동화하고 구현하기 편하게 할 뿐만 아니라, 팀단위의 협업도 용이하게 하는 것이다.
분산, 병렬 처리 소프트웨어 프레임워크가 스칼라와 같은 함수형 언어와 결합되어 있는 경우 워크플로우 기술을 통해 기술된 빅데이터 가공, 처리 프로세스는 더욱 강력해진다. 스칼라와 같이 반영(reflection)과 같은 메타프로그래밍이 지원되는 함수형 언어로 기술되는 분산, 병렬 처리 과정은 워크플로우 기술로 표현, 통합되기에 용이하다. 이 때문에 스칼라 언어로 작성된 스파크와 같은 분산, 병렬 처리 소프트웨어로 기술된 빅데이터 처리 과정은 워크플로우 형태로 관리하고 자산화하기 좋다.
애초에 IT 산업계에서 빅데이터라는 말이 화두가 되었던 것은 빅데이터 처리를 위한 자원 관리와 조율을 위한 클라우드 기술과 구글의 맵리듀스, 아파치 하둡과 같은 분산, 병렬 처리 프레임워크 기술 덕분이었다. 이런 이유로 빅데이터 문제를 클라우드와 하둡기술만 쓰면 다 해결할 수 있는 것 같은 인식이 한동안 IT 업계에 널리 퍼져 있었지만, 사실은 빅데이터가 빅데이터를 활용하는 비즈니스에서 가치를 더하기 위해서는 다양한 IT 기술을 적절하게 활용해야 한다는 것을 다시 한번 강조하고 싶다.
그럼에도 불구하고, 빅데이터 붐을 일으킨 하둡과 같은 분산, 병렬 처리 소프트웨어 기술이 여전히 빅데이터 비즈니스의 핵심 기술 중의 하나인 것은 분명하다. 위에서 언급한 네 가지 사항을 염두에 두고, 빅데이터에서 비즈니스 가치를 뽑아내기 위한 현실적인 준비와 실행을 하도록 하자. 더 이상 하둡이나 스파크 인프라를 한번 구축하고 끝나는 식의 빅데이터 기술 붐이 아니라, 빅데이터를 기반으로 한 지능형 서비스와 비즈니스 효율화, 자동화로 우리 사회가 더욱 풍성하고 편리하게 발전하도록 돕는 빅데이터 활용이 되었으면 한다.
[참고문헌]
[1] 김진철, “LHC에서 배우는 빅데이터와 machine learning 활용 방안”, 2016년 9월 28일, A CIO Conversation for Technology Leadership – Breakfast Roundtable 발표 자료
[2] G. GANIS, “PROOF – Present and Future,” Technology Seminar, BNL, April 25 2008.
[3] B. Bellenot, R. Brun, G. Ganis, J. Iwaszkiewicz, F. Rademakers, M. Ballintijn, “PROOF: Parallel ROOT Facility – Poster Presentation.“
[4] Maarten Ballintijn, Gunther Roland, Rene Brun, Fons Rademakers, “The PROOF Distributed Parallel Analysis Framework based on ROOT,” ArXiv preprint: physics/0306110v1, https://arxiv.org/abs/physics/0306110v1.
[5] D. Piparo, “Expressing Parallelism with ROOT,” CHEP 2016.
[6] ROOT Documentation - The Event Display classes, https://root.cern.ch/root/html/GRAF3D_EVE_Index.html .
[7] ROOT Documentation - An event display based on ROOT GUI, https://root.cern/event-display-based-root-gui .
[8] Fabian Glaser, Helmut Neukircheny, Thomas Rings, Jens Grabowski, “Using 맵리듀스 for High Energy Physics Data Analysis,” Proceedings of the 2013 International Symposium on 맵리듀스 and Big Data Infrastructure (MR.BDI 2013), 03-05 December 2013, Sydney, Australia 2013. DOI: 10.1109/CSE.2013.189, IEEE 2013. (https://goo.gl/Fxf9vp)
[9] Jim Pivarski, “Lowering boundaries between data analysis ecosystems,” in Future Trends in Nuclear Physics Computing Workshop, at CEBAF Center, Jefferson Lab ( F113 ), May 3, 2017. (https://www.jlab.org/indico/event/213/)
[10] Evangelos Motesnitsalis, “Physics Data Analytics and Data Reduction with 아파치 스파크,” XLDB 2017, 10 Oct. ~ 12 Oct., 2017.
[11] Oliver Gutsche, Luca Canali, Illia Cremer, Matteo Cremonesi, Peter Elmer, Ian Fisk, Maria Girone, Bo Jayatilaka, Jim Kowalkowski, Viktor Khristenko, Evangelos Motesnitsalis, Jim Pivarski, Saba Sehrish, Kacper Surdy, Alexey Svyatkovskiy, “CMS Analysis and Data Reduction with 아파치 스파크,” ArXiv Preprint:1711.00375, https://arxiv.org/abs/1711.00375 .
[12] Stefano Alberto Russo, “Using the 하둡/맵리듀스 approach for monitoring the CERN storage system and improving the ATLAS computing model,“ CERN Document Archive: CERN-THESIS-2013-067, 2013.
[13], CERN IT-DB, 하둡 and Analytics at CERN IT, Meeting with Microsoft, 7 November 2016. (https://goo.gl/JeGkWU)
[14] C Nieke, M Lassnig, L Menichetti, E Motesnitsalis, and D Duellmann, “Analysis of CERN computing infrastructure and monitoring data,” Proceedings of the 21st International Conference on Computing in High Energy and Nuclear Physics (CHEP2015), Journal of Physics: Conference Series 664, 052029, 2015.
[15] Jim Pivarski, “Reading ROOT data in Java and 스파크,” Princeton University – DIANA Seminar, 7 November, 2016.
[16] S. A. Russo, M. Pinamonti and M. Cobal, “Running a typical ROOT HEP analysis on 하둡 apReduce,” Proceedings of the 20th International Conference on Computing in High Energy and Nuclear Physics (CHEP2013), Journal of Physics: Conference Series 513, 032080, 2014.
[17] Andrew Hanushevsky and Daniel L. Wang, Scalla: Structured Cluster Architecture for Low Latency Access,” Proceedings of the 2012 IEEE 26th International Parallel and Distributed Processing Symposium Workshops & PhD Forum, pp. 1168-1175, 2012. (doi>10.1109/IPDPSW.2012.141, https://goo.gl/ATwsoo)
[18] Boduo Li, Edward Mazur, Yanlei Diao, Andrew McGregor, Prashant Shenoy, “SCALLA: A Platform for 스칼라ble One-Pass Analytics using 맵리듀스,” ACM Transactions on Database Systems (TODS), Vol. 37 Iss. 4, December 2012. (https://goo.gl/LJT4o2 , https://goo.gl/UPAS1F)
[19] Z. Baranowski, L. Canali, R. Toebbicke, J. Hrivnac, D. Barberis, “A study of data representation in 하둡 to optimize data storage and search performance for the ATLAS EventIndex,” Journal of Physics: Conf. Series 898, 062020, 2017. (doi :10.1088/1742-6596/898/6/062020)
[20] C. Luzzi, L. Betev, F. Carminati, C. Grigoras, A. Manafov and P. Saiz, “Dynamic parallel ROOT facility clusters on the Alice Environment,” Proceedings of the International Conference on Computing in High Energy and Nuclear Physics 2012 (CHEP2012), Journal of Physics: Conference Series 396, 032068, 2012. (doi:10.1088/1742-6596/396/3/032068)
[21] P. Andrade, B. Fiorini, S. Murphy, L. Pigueiras, M. Santos, “Monitoring Evolution at CERN,” Proceedings of the 21st International Conference on Computing in High Energy and Nuclear Physics (CHEP2015), Journal of Physics: Conference Series 664, 052002, 2015. (doi:10.1088/1742-6596/664/5/052002)
[22] Zbigniew Baranowski, Maciej Grzybek, Luca Canali, Daniel Lanza Garcia, Kacper Surdy, “Scale out databases for CERN use cases,“ Proceedings of the 21st International Conference on Computing in High Energy and Nuclear Physics (CHEP2015), Journal of Physics: Conference Series 664, 042002, 2015. (doi:10.1088/1742-6596/664/4/042002)
*김진철 박사는 1997년 한국과학기술원에서 물리학 학사, 1999년 포항공과대학교에서 인공신경망에 대한 연구로 석사 학위를, 2005년 레이저-플라즈마 가속기에 대한 연구로 박사 학위를 받았다. 2005년부터 유럽입자물리학연구소(CERN)의 LHC 데이터 그리드 구축, 개발에 참여, LHC 빅데이터 인프라를 위한 미들웨어 및 데이터 분석 기술을 연구하였다. 이후 한국과학기술정보연구원(KISTI), 포항공과대학교, 삼성SDS를 거쳐 2013년부터 SK텔레콤에서 클라우드 컴퓨팅과 인공지능 기술을 연구하고 있다. 빅데이터와 인공지능 기술의 기업 활용 방안에 대해 최근 다수의 초청 강연 및 컨설팅을 수행하였다. ciokr@idg.co.kr
※ 본 내용은 한국IDG(주)(http://www.ciokorea.com)의 저작권 동의에 의해 공유되고 있습니다.
Copyright ⓒ CIO Korea. 무단전재 및 재배포 금지

| 번호 | 제목 | 작성 | 조회수 |
|---|---|---|---|
| 514 | [빅데이터] 김진철의 How-to-Big Data | 빅데이터 주요 기술의 조건 (1) file | 2018-05-24 | 2724 |
| 513 | 기업용으로 '괜찮은' 오픈소스 웹 서버 7선 | 2018-05-09 | 6550 |
| 512 | IT관리자를 위한 오픈소스 네트워크 모니터링 툴 19선 | 2018-01-16 | 17362 |
| 511 | 젠킨스란 무엇인가, CI(Continuous Integration) 서버의 이해 | 2017-12-13 | 4431 |
| 510 | [사물인터넷] 사물 인터넷 정의 : 필수 IoT 용어 가이드 | 2017-11-02 | 2486 |
| 509 | [인공신경망] (3) 신경망 번역, 데이터베이스 확보와 오픈소스 플랫폼 경쟁 시작 | 2017-10-10 | 2534 |
| 508 | [OS] 소규모 서버의 간편한 활용을 위한 대안 ClearOS | 2017-08-21 | 2799 |
| 507 | 디자이너를 위한 오픈소스 프로젝트 | 2017-08-18 | 2304 |
| 506 | [웹로그분석툴] Google Analytics를 대체할만한 오픈소스 웹 로그 분석 도구 Piwik 소개 | 2017-08-16 | 4185 |
| 505 | [Chrome] How-To : 크롬에서 일어나는 플래시 충돌 오류 해결하기 | 2017-08-04 | 3160 |
0개 댓글