


Martin Heller, Ian Pointer | InfoWorld / 2018-10-06
아마존, 구글, 마이크로소프트, 페이스북, 그리고 수많은 업체가 가장 풍부하고 가장 쉬운 머신러닝 및 딥러닝 라이브러리를 만들기 위해 경쟁하고 있다. 경쟁은 좋은 것이다. 2018년 최괴의 오픈소스 소프트웨어 대상 머신러닝 부문은 모델을 구축하고 훈련하는 데 필요한 최첨단 프레임워크와 최신 툴, 클러스터 전반에 딥러닝을 배포하기 위한 플랫폼 등이 차지했다. editor@itworld.co.kr

텐서플로우(TensorFlow)
필자가 2018년 1월 텐서플로우를 리뷰한 이래, 이 보편화된 딥러닝용 신경망 프레임워크는 5차례의 버전 업그레이드가 이루어지면서 더 쉽고 강력해졌다. 주요 신기능 및 개선으로는 데이터 소스인 구글 클라우드 빅테이블의 통합, 향상된 tf.kera 모듈, 모바일 기기에 최적화된 모델 생성, 개선된 데이터 로딩 및 텍스트 처리, GPU 메모리로의 데이터 프리페칭, 개선된 구글 클라우드 TPU 사용 성능, 즉시 실행(eager execution) 모드의 전적인 지원 상태로의 격상 등이 있다. 즉시 실행은 그래프를 구축한 후 실행하는 것보다 더 이해하기 쉬운 명령형 프로그래밍 스타일을 제공한다.

케라스(Keras)
케라스는 심층 신경망 프레임워크를 가능한 한 단순화시켰다. 계층당 1줄의 파이썬 코드, 그리고 순차 모델을 이용하며 모델을 컴파일하고 훈련시키는 데 각각 1회의 호출이면 충분하다. 함수형 API를 통해 임의 토폴로지(arbitrary topologies) 역시 지원한다. 텐서플로우, 테아노, CNTK2를 백엔드로 이용하고, 이에 의해 GPU를 원활하게 지원한다(그리고 텐서플로우를 이용한 구글 클라우드 상의 TPU). 케라스는 훈련 시 넘피 배열(Numpy arrays)을 입력으로 이용하지만, 파이썬 제너레이터 인터페이스를 통해 다른 포맷도 지원할 수 있다. 클라우드 서비스로부터 모바일 기기에 이르기까지 다채로운 배치 옵션을 제공한다.
파이토치(PyTorch)
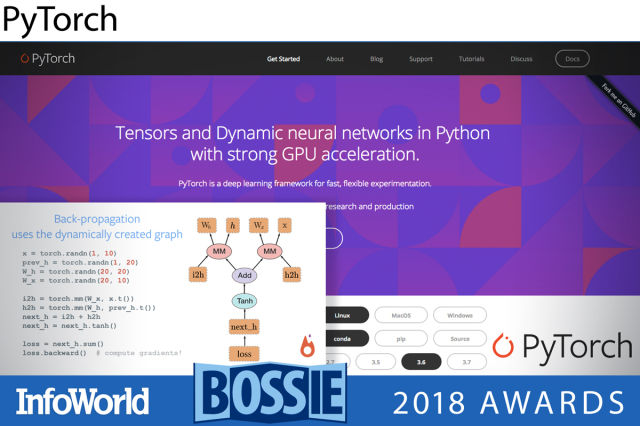
파이토치는 파이썬을 스크립트 언어로 이용하는 고급 심층 신경망이고, 진화된 토치 C/CUDA 백엔드를 이용한다. 카페2(Caffe2)의 프로덕션 기능들 역시 파이토치 프로젝트에 통합되었다. 파이토치는 다이내믹 신경망을 특징으로 하고, 이는 네트워크 토폴로지 자체가 훈련 중의 이터레이션에 따라 변할 수 있다는 의미이다. 정적 네트워크보다 디버깅이 더 수월하고 이터레이션이 더 빠른 다이내믹 네트워크를 위해 파이토치 프로그램은 프로그램 실행 중에 그래프를 생성한다. 그 후 백프로퍼게이션(backpropagation)이 동적으로 생성된 그래프를 이용하면서 그라디언트(gradients)를 저장된 텐서 상태로부터 자동으로 계산한다. 파이토치는 성숙한 토치 프레임워크 상에서 구축되었으므로 이미 강력한 신경망 계층, 최적화 알고리즘, 손실 함수를 보유하고 있다.
Fast.ai
Fast.ai는 딥러닝 MOOC일뿐 아니라 파이토치 상에 구축된 딥러닝 라이브러리이기도 하다. Fast.ai 프레임워크는 모델을 구축하고 훈련시키기 위한 일관되고 확고한 래퍼(wrappers)를 제공하고, 아울러 딥러닝 모델을 훈련시키는 최첨단 기법을 일부 통합시키기도 했다(순환 학습 속도 및 NLP 문제 분야에 대한 전이 학습 기법 등). 다시 말해 Fast.ai는 캐글 대회 및 실제 프로덕션 애플리케이션을 위한 모델을 구축하는데 유용하다. 무엇보다, 이는 아마 딥러닝 세계로 들어가는 가장 쉬운 길일 것이다.

체이너 (Chainer)
체이너는 유연한 파이썬 신경망 프레임워크이다. 신경망 토폴로지를 우선적으로 정의하고 고정하는 프레임워크들과 달리, 체이너는 실행 중 정의 체제를 이용한다. 따라서 네트워크는 실질적인 진행형 연산을 통해 동적으로 정의된다. 백프로퍼게이션 연산은 그라디언트 배열을 계산하고, 갱신된 중량을 찾아 옵티마이저를 호출한다. 체이너는 큐피(CuPy)를 GPU 연산을 위한 백엔드로 이용하고, 이는 차례로 CUDA와 cuDNN을 호출한다. 특히 cupy.ndarray 클래스는 체이너를 위한 GPU 어레이 구현이다. 호환 인터페이스에 의해 넘피(NumPy)의 기능을 부분적으로 지원한다. 체이너는 최근의 다른 신경망 프레임워크에 영향을 주었다. 파이토치(PyTorch) 또한 동적 신경망을 이용하고, 텐서플로우의 즉시 실행 모드도 마찬가지이다.

H2O
필자는 2017년 말 H2O.ai의 드라이버리스 AI(Driverless AI)를 리뷰할 때부터 피처 엔지니어링 및 주석 역시 수행하는 이 자율 구동 머신러닝 시스템을 좋아했다. 그 당시, 드라이버리스 AI를 위해 제반 머신러닝을 수행하는 오픈소스 H2O 스택 위에 구축되고, 자체적인 오토 ML 및 데이터 준비 모듈을 갖추었다고 설명했다. H2O는 선형 확장성을 가진 분산 인메모리 머신러닝 플랫폼이다. 그라디언트 부스팅 머신, 일반화 선형 모델, 딥러닝 등 가장 널리 쓰이는 통계 및 머신러닝 알고리즘을 지원한다. H2O는 R, 파이썬, 스칼라, 자바, 그리고 자체 상호작용형 노트북에서의 프로그래밍을 지원한다.

마이크로소프트 코그니티브 툴킷
마이크로소프트 코그니티브 툴킷((Microsoft Cognitive Toolkit, CNTK)은 스카이프, 코타나, 빙, 엑스박스 등 마이크로소프트 서비스의 AI 기능 기저에 놓인 딥러닝 툴킷이다. 파이썬, C++, 브레인스크립트로부터의 다차원적 밀집 또는 희소 데이터를 처리하고, 다채로운 신경망 유형을 포함한다. 예컨대 피드포워드(FeedForward, FFN), 컨볼루셔널(Convolutional, CNN), RNN/LSTM(Recurrent/Long Short Term Memory), 배치 정규화(batch normalization), 시퀀스-투-시퀀스 메커니즘 등이다. 코그니티브 툴킷은 강화 학습, 생성적 적대 신경망, 지도 및 비지도 학습, 자동 하이퍼파라미터 튜닝을 지원하고, 파이썬으로부터 GPU 상에 새 이용자 정의 핵심 컴포넌트를 추가할 수 있는 기능을 지원한다. 다중 GPU 및 머신 상에서 병렬성을 정확히 수행할 수 있고, 아무리 큰 모델이라도 GPU 메모리에 맞출 수 있다.

MXNet
이 딥러닝 프레임워크가 2016년 처음 나왔을 때 2가지 이유에서 흥미로웠다. 우선 다수의 GPU에 걸쳐 다수의 네트워크 인스턴스에 잘 적응했고, 아마존이 선호하는 심층 신경망 프레임워크였다. 그러나 당시에는 완성도가 부족한 편이었다. MXNet은 2017년 초 아파치 소프트웨어 재단 산하로 옮겨졌고, v1.2.1이지만 아직도 ‘배양기’에 있다고 여겨진다. 그러나 완성도가 더 이상 부족하지는 않다. 믹스넷은 디바이스 상의 데이터 구조 배치에 대한 우수한 제어, 다중 GPU 트레이닝, 자동 미분, 최적화된 사전 정의 신경망 계층을 자랑한다. 글루온(Gluon)으로 신속히 훈련시킬 수 있는 사용이 쉬운 인터페이스를 갖추었다. 글루온 이전에는 간단한 명령 코드나 신속한 심볼 코드를 작성할 수 있었지만, 2가지를 동시에 할 수는 없었다.
피처툴(Featuretools)
피처툴은 자동 피처 엔지니어링을 위한 오픈소스 파이썬 라이브러리이다. 데이터 과학에 식견이 있는 사람이라면 원시 데이터를 유의미하고 정규화된 피처(features)로 수동으로 변환하기가 얼마나 까다롭고 시간이 많이 드는지 안다. H2I.ai의 독점 소프트웨어인 드라이버리스 AI는 거의 캐글 그랜드 마스터에 의해 달성된 수준까지 피처 엔지니어링의 자동화를 보여주었다. 피처툴은 심층 피처 합성을 구현한다. 원시 데이터를 사용자가 아는 것과 결합해 머신러닝 및 예측 모델링을 위한 유의미한 피처를 구축할 수 있다. 유효 데이터만이 연산에 사용될 수 있도록 해 피처 벡터를 흔한 라벨 유출 문제로부터 안전하게 유지할 수 있는 API를 제공한다.
호러보드(Horovod)
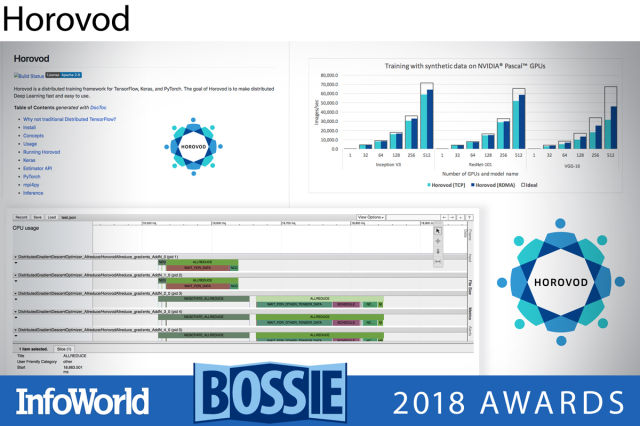
우버가 개발한 호러보드는 텐서플로우, 케라스, 파이토치를 위한 분산 훈련 프레임워크이다. 호러보드의 목표는 분산 딥러닝을 신속하고 사용하기 쉽게 만드는 데 있다. 바이두의 텐서플로우 링올리듀스(ring-allreduce) 알고리즘의 드래프트 구현으로부터 아이디어를 차용하고 그 위에 구축된다. 노드 간의 메시지 전달을 위해 오픈 MPI(Open MPI)를 이용하고, 고도로 최적화된 링올리듀스 버전을 위해 NCCL(Nvidia Collective Communications Library)를 이용한다. 호러보드는 무려 512개의 엔비디아 파스칼 GPU를 사용하면서, 인셉션 V3 및 레스넷-101에 대해 90%의 스케일링 효율, VGG-16에 대해 68%의 스케일링 효율을 달성한다.
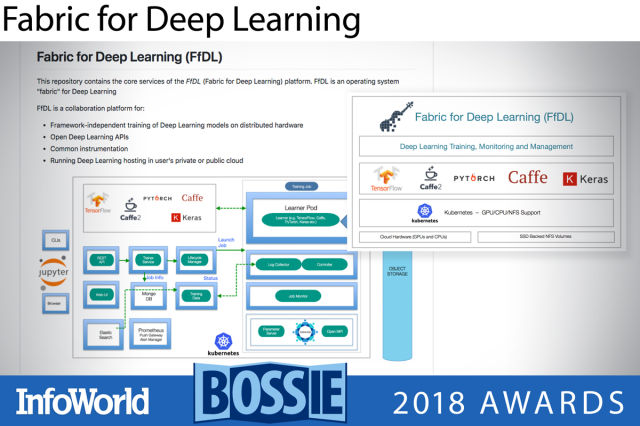
딥러닝용 패브릭(Fabric for Deep Learning)
딥러닝용 패브릭(FfDL)은 피들이라고 부리기도 하는 딥러닝 플랫폼으로, 쿠버네티스 상에서 텐서플로우, 카페, 파이토치, 케라스, H2O를 서비스로서 제공한다. 원래 IBM 클라우드를 위해 개발되었지만, 쿠버네티스 클러스터를 지원하는 다른 클라우드에서도 실행할 수 있고, Kubeadm-DINI를 통해 도커 상에서 로컬로도 실행될 수 있다. 쿠버네티스에서 디바이스 플러그인을 이용하고 딥러닝 프레임워크의 GPU 지원 빌드를 선택한다면 피들은 GPU를 지원할 것이다. 피들은 맥OS 및 리눅스에서만 테스트되었다.
※ 본 내용은 한국IDG(주)(http://www.itworld.co.kr)의 저작권 동의에 의해 공유되고 있습니다.
Copyright ⓒITWORLD. 무단전재 및 재배포 금지
[원문출처 : http://www.itworld.co.kr/slideshow/110976]

| 번호 | 제목 | 작성 | 조회수 |
|---|---|---|---|
| 554 | 2018 최고의 오픈소스 소프트웨어 : 머신러닝 | 2018-10-08 | 3331 |
| 553 | 2018 최고의 오픈소스 소프트웨어 : 클라우드 컴퓨팅 | 2018-10-05 | 3295 |
| 552 | 2018 최고의 오픈 소스 소프트웨어 : 소프트웨어 개발 | 2018-10-04 | 2857 |
| 551 | 쿠버네티스 서비스(kubernetes services) (2) | 2018-09-27 | 2280 |
| 550 | 쿠버네티스 서비스(kubernetes services) (1) | 2018-09-27 | 3106 |
| 549 | 쿠버네티스(kubernetes) 구성요소 | 2018-09-21 | 3697 |
| 548 | 쿠버네티스(kubernetes) 아키텍처 | 2018-09-21 | 3190 |
| 547 | kubernetes 로 컨테이너 실행해 보기 | 2018-09-20 | 11155 |
| 546 | 쿠버네티스 구성요소 : 객체(Object), 컨트롤러(Controller), 템플릿(Template) | 2018-09-20 | 1577 |
| 545 | 윈도우에 docker, kubernetes 설치하기 | 2018-09-20 | 4570 |
0개 댓글