


ⓒ 공개SW역량프라자 / 2016-09-27
추천시스템(Recommendation System)이란 대상자가 좋아할 만한 무언가를 추천하는 시스템을 일컫는다. 아마 오늘, 지금 이순간 이글을 읽고있는 독자 중 대부분은 자신이 인지하던 인지하지 않던간에최소한 한 번쯤은 이미 추천시스템을 경험했을 것이다.
추천시스템은 아마도 일반인들이 가장 빈번하게 접하는 머신러닝 서비스라고 얘기해도 절대 과언은 아닐 것이다. 그만큼 추천시스템, 특히 IT서비스에서는 매우 중요한 핵심적인 기술이라고 할 수 있고, 거의 모든 IT 서비스 관련 회사들은 추천시스템을 운영하고 있다.
추천시스템은 사용자의 주의를 환기시킬 수 있고, 더 나아가 새로운 콘텐츠의 발견, 궁극적으로 매출증대로 연결시킬 수 있기 때문에 기업들 입장에서는 매력적인 기술이다.
아마존의 경우 1/3의 주문이 추천시스템에 의해 이뤄지고 있고, 넷플릭스는 ¾이 그것에 의한 것이라고 할 정도로 ROI가 높은 기술중의 하나이다.
이처럼 추천시스템은 서비스에 큰 영향을 미치는 요소이기 때문에 오래전부터 많은 학자들과 기업들에서 연구하고 있는 주요한 분야 중의 하나이다.
본고에서는 선두기업들의 추천시스템활용과 주요한 기술들에 대해 알아보고자 한다.
[목차]
Recommendation System이란? |
추천시스템(Recommendation System)이란?
얼마 전에 타계한 앨빈 토플러의 저서, "제 3의 물결"에서 이미 이야기한 것과 같이 원시 시대에 수렵으로 생명을 이어가던 인류는 BC 7천년경 신석기 혁명(Neolithic Revolution)으로 불리우는 농업 혁명을 통해서 정착을 시작하고 국가와 문화를 만들 수 있었고, 다시 18세기 중반부터 시작된 산업 혁명으로 인구를 폭발적으로 증가시킬 수 있었다. 그리고 2차 대전을 거치면서 정보 혁명에 이은 새로운 시대를 맞이하였다.
Figure 1 Netflix 화면
추천시스템(RecommendationSystem)이란 대상자가 좋아할 만한 무언가를 추천하는 시스템을 일컫는다. 아마 오늘, 지금 이순간 이글을 읽고있는 독자 중 대부분은 자신이 인지하던 인지하지 않던 간에 최소한 한 번쯤은 이미 추천시스템을 경험했을 것이다.쇼핑을 하기 위해 웹사이트를 방문하면 당신에게 추천할 만한 아이템이라는 것을 보거나 혹은 특정 상품의 정보를 얻기 위해 클릭을 하면화면 어딘가에 추천아이템, 인기아이템, 당신이 좋아할 만한아이템 등 다양한 이름으로 상품을 추천하는 것을 쉽게 발견할 수 있다. 뉴스도 역시 예외가 아니다. 당신이 클릭한 뉴스를 보여주는 웹페이지 어딘가에는 쇼핑과 마찬가지로 당신이 좋아할 만한, 관심을 가질만한 기사가 나타나 있을 것이다. 간단히 쇼핑과 뉴스에대해서 예를 들었듯이 추천시스템은 도처에 널려있으며, 그것이 적용되는 범위도 쇼핑, 뉴스, 친구추천, 음악, 영화, 변호사 추천 등 매우 광범위하다고 할 수 있다.
추천시스템은 아마도 일반인들이 가장 빈번하게 접하는 머신러닝서비스라고 얘기해도 절대 과언은 아닐 것이다. 그만큼 추천시스템, 특히IT서비스에서는 매우 중요한 핵심적인 기술이라고 할 수 있고, 거의모든 IT 서비스 관련 회사들은 추천시스템을 운영하고 있다.
추천시스템은 사용자의 주의를 환기시킬 수 있고, 더 나아가 새로운 콘텐츠의 발견, 궁극적으로 매출증대로 연결시킬수 있기 때문에 기업들 입장에서는 매력적인 기술이다.
아마존의 경우 1/3의주문이 추천시스템에 의해 이뤄지고 있고, 넷플릭스는 ¾이그것에 의한 것이라고 할 정도로 ROI가 높은 기술중의 하나이다.
이처럼 추천시스템은 서비스에 큰 영향을 미치는 요소이기때문에 오래전부터 많은 학자들과 기업들에서 연구하고 있는 주요한 분야 중의 하나이다.
본고에서는 선두기업들의 추천시스템활용과 주요한 기술들에 대해 알아보고자 한다
추천시스템(Recommendation System) 활용사례
아마존
아마존은 전자상거래분야에서 추천시스템의 선구자라고 할수 있다.
아마존은 사업 초기부터 추천시스템의 가치를 알아보고 이를전자상거래에 활용하기 위한 방법을 모색해온 몇 안되는 회사이다.
아마존은 평점(Rating),구매행위(Buying Behavior) 그리고 검색행위(BrowsingBehavior) 정보들을 이용해 추천시스템을 운영하고 있다. 특히 Rating이 추천시스템에 있어서 중요한 역할을 하는데 아마존에서는 이를 명시적인 평점(Explicit Rating)와 암묵적인 평점(Implicit Rating)의 2가지로 구분해 활용하고 있다. 명시적인 평점은 사용자가 직접 주는평점을 의미하는 것이고, 암묵적인 평점은 구매행위와 피드백을 가공해 사용하고 있다.
넷플릭스
비디오 스트리밍회사로 잘 알려져 있는 넷플릭스 역시 아마존과 마찬가지로 추천시스템의 열렬한 신봉자라고 할 수 있다. 넷플릭스 서비스의 핵심적인 기술요소는 추천시스템으로 사용자의 성향을 파악해 좋아할 만한 영화를 추천해주는 단순한 시스템에서 출발했지만 최근에는 사용자가 로그인하는 순간 해당 사용자의 취향에 맞춰 전체 페이지가 구성되는 수준까지 발전했다.
넷플리스는 자사의 추천시스템보다 10%이상 성능을 향상 시킬 수 있는 방법을 제시한 팀에게 상금을 주는 “Netflix Prize Contest“라는 것을 개최해 머신러닝 발전에 혁혁한 공을 세우기도 했다.
Netflix Prize Contest를 통해 SVD(Singular Value Decomposition, 특이값 분해)과 ensemble의 중요성 등이 많이 부각되었고, 우승팀이 사용했던 방법과 수학이론들을 많은 데이터과학자들과 머신러닝 개발자들에게 영감을 주었다.
페이스북
페이스북 역시 추천시스템을 적극적으로 활용중인 회사인데 앞서 언급한 회사들과는 다르게 상품이나 뉴스 추천이 아니라 친구추천을 하는데 활용하고 있다.
친구추천은 전통적인 추천시스템의 대상이었던 상품과는 다른 성격을 가지고 있다.
상품추천의 목적은 매출의 증대와 같은 직접적인 목적을 가지고 있는 반면에 친구추천은 서로의 교류를 증대 시킬 목적을 가지고 있기 때문에 Link Prediction이라는 것에 중점을 두고 있다.
추천시스템의 주요기술
협업필터링(Collaborative Filtering)
협업필터링은 다음과 같은 가정을 기반으로 만들어진 기술로 추천시스템의 가장 기본적이면서도 중요한 핵심기술이라고 할 수 있다.
類類相從(유유상종) : 끼리끼리 모인다.
예를 들어 A라는 사람이 부산행이라는 영화를 좋아하면, A와 성향이 비슷해 보이는 B라는 사람 역시 부산행을 좋아할 것이라는 생각을 활용한 방법이다.
이 아이디어는 매우 단순한 생각이지만 현실세계에서 매우 잘 동작하는 것 중의 하나로 거의 모든 추천시스템에서 활용하고 있는 기술이다.
상식적으로 생각해도 유사한 성향을 가진 사람들은 관심사가 유사하다는 것은 우리 역시 경험적으로 알고 있기 때문에 이 단순한 아이디어가 왜 좋은 성능을 보여주는지는 잘 이해할 수 있을 것이다.
Collaborative Filtering은 “類類相從”의 아이디어를 활용한 것이라 했는데, 여기서 類類相從의 대상이 무엇이냐에 따라 User-based Collaborative Filtering(사용자기반 협업 필터링)과 Item-based Collaborative Filtering(아이템기반 협업 필터링)의 2가지로 나뉘어 진다.
사용자기반 협업 필터링(User-based Collaborative Filtering)
이 방법은 유사한 성향을 가진 사람들을 구분하고, 해당 성향의 사람들이 좋아하는 것을 이용해 추천하는 방식이다.
앞서 예를 든 영화처럼 A와 B가 비슷한 성향을 가진 사람인데 A가 자전거를 좋아한다면 B역시 자전거를 좋아할 것이라 예측하고 자전거관련 상품이나 정보를 추천하는 방식이다.
보다 구체적인 설명을 하기 위해 다음과 같은 데이터가 있다고 하자.
Item1 |
Item2 |
Item3 |
Item4 |
Item5 |
|
User1 |
5 |
3 |
4 |
4 |
? |
User2 |
3 |
1 |
2 |
3 |
3 |
User3 |
4 |
3 |
4 |
3 |
5 |
User4 |
3 |
3 |
1 |
5 |
4 |
User5 |
1 |
5 |
5 |
2 |
1 |
위의 데이터는 User1,2,3,4,5가 Item 1,2,3,4,5에 매긴 평점을 나타내는 것이다.
예를 들어 User1은 item1에 대해 5점이라는 평점을 주었고, User3는 item4에 대해 3이라는 평점을 주었다.
이제 User1에게 Item5를 추천하는 것이 적당한지를 판별하기 위해 User1과 비슷한 성향을 가진 사용자를 찾고 해당 사용자가 Item5에 준 평점이 높다면, 아마도 User1은 Item5를 좋아할 것이라고 생각하고 추천한다.
문제는 위의 표에서 User1과 가장 유사한 성향을 가진 사람이 누군지를 파악하는 것이다.
유사한 성향을 유사도(Similarity)라고 하며 유사도가 높다는 것은 그만큼 서로 유사한 성향을 가졌다고 할 수 있다.
유사도는 협업 필터링에서 중요한 척도이다. 왜냐하면 이 척도를 이용해 사용자 간의 유사도, 혹은 아이템 간의 유사도를 계산할 수 있기 때문이다.
계산된 유사도를 이용해 가장 유사하다고 생각되는 사람이나 아이템을 선정할 수 있고, 그 선정된 것에 의해 사용자에게 무엇을 추천하는 것이 좋은지를 결정할 수 있다.
아래의 식은 많이 활용되는 피어슨 상관계수를 이용한 유사도를 계산하는 식이다.
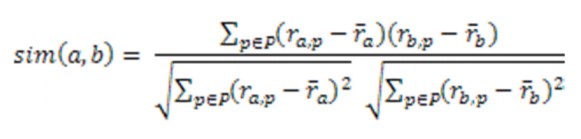
Figure 2 Similarity - Pearson's Correlation
피어슨상관계수는 비교대상이 되는 2개의 변수가 선형적인 관계를 추정하는 방법으로 변수들의 값이 동일한 방향으로 움직이는지, 그렇지 않은지를 파악해 비례관계인지, 반비례관계인지 아니면 관계가 없는지를 추정할 수 있다.
위의 식을 이용해 User1과 다른 사용자들간의 유사도를 계산해보면 다음과 같다.
- Sim(User1, User2) = 0.85
- Sim(User1, User3) = 0.70
- Sim(User1, User5) = -0.79
위의 값에서 알 수 있듯이 User1과 가장 유사한 사람은 User2라는 것을 알 수 있다.
User2의 Item5의 평점은 3점이라는 것을 알 수 있다.
하지만 User2의 평점이 3점이라는 것을 User1이 Item5에 대한 평점이라고 생각하기는 어렵다. 왜냐하면 User2의 성향이 평점을 낮게 주거나 혹은 반대로 평점을 많이 준다면 3점이라는 평점을 그대로 3점의 평점으로 받아 들일 수 없기 때문이다.
따라서 이를 보완한 새로운 방법이 필요하다.
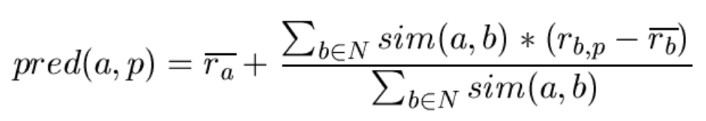
Figure 3 Prediction Function
위의 식은 언급한 문제점을 해결하기 위한 방법으로 (r_a ) ̅ 의 값을 기준값으로 설정하고, 유사도에 따른 다른 사용자의 평점을 이용해 가중치를 조절하는 방식으로 최종적으로 User가 특정 Item을 좋아할지 말지를 계산한다.
아이템기반 협업 필터링(Item-based Collaborative Filtering)
이 방식은 앞서 설명한 사용자기반 협업 필터링과 모든 아이디어가 동일하지만 대상이 사람이 아닌 아이템으로 대치된 것이다.
예를 들어 A에게 물건을 추천한다면 A가 과거에 좋아했던 물건을 찾고 해당 물건과 유사한 물건을 추천해주는 방식이다.
기본적인 아이디어와 방법이 앞서 설명한 방법과 유사하기 때문에 생략하고 아이템기반 협업 필터링에서 많이 사용하는 유사도 계산방법인 코사인유사도(Cosine Similarity)에 대해 설명한다.
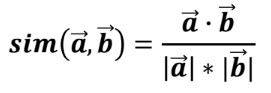
Figure 4 Cosine Similarity
코사인유사도는 평점을 벡터로 생각하고, 2개 벡터사이의 각도를 계산하고, 그 각도가 작을수록 가까이 있기 때문에 유사하다고 판단하는 방식이다.
사용자기반 협업 필터링과 아이템기반 협업 필터링을 Memory-based Methods라고 한다. 이 기술의 가장 큰 장점은 구현이 간단하고 이해하기 쉽다는데 있다. 유사도를 구하거나, 예상평점을 구하는 것이 일반적인 머신러닝처럼 대량의 데이터를 이용해 모델을 만들고, 해당 모델의 평가를 하고, 이를 최적화하는 과정이 필요치 않고 단순한 몇가지의 수식으로 쉽게 계산이 가능하다.
단점은 평점에 대한 정보가 많지 않은 경우에는 예측의 정확도가 높지 않은 것이다.
예를 들어 사용자에게 “Machine Learning by Example” 이라는 책을 추천하려고 하는데, 이 책이 신간이라 아직 평점이 없다면 Collaborative Filtering은 적절한 평점을 예측할 수 없다. 그리고 이와 더불어 범위성(Scalability) 문제가 있어 사용자나 아이템이 매우 많다면 실시간으로 사용하는데 계산시간이 오래걸리기 때문에 적용하기 어렵다.
모델기반 방법(Model-based Methods)
이 방식은 머신러닝을 이용해 평점을 예측할 수 있는 모델을 만드는 방식이다.
앞서 예기한 Memory-based 방식에서는 별도의 모델을 만들지 않았기 때문에 평점을 가지고 있지 않은 것에 대해서는 효과가 없었던 반면 Model-based 방법에서는 과거의 사용자 평점 데이터를 이용해 모델을 만들었기 때문에 평점 정보가 없다하더라도 특정 아이템에 대한 사용자의 평점을 예측할 수 있다. 의사결정트리, SVM등의 머신러닝 알고리즘을 이용해 평점예측모델을 만든다.
모델을 만드는데 사용되는 방법들은 다음과 같다.
- Matrix Factorization
- SVD(Singular Value Decomposition), PCA(Principal Component Analysis) - Association Rule Mining
- Shopping basket analysis - Probabilistic Models
- Clustering, Bayesian networks - Other Techniques
- Regression, Deep Learning, SVM
Model-based 방법에는 여러가지가 있지만 Netflix Prize Contest를 통해 대부분의 추천시스템에서 사용되는 중요한 기술인 SVD(Singular Value Decomposition)에 대해서 설명한다.
SVD는 차원축소기술(Dimensionality Reduction)의 일종으로 사용자와 아이템의 평점데이터를 행렬로 생각하고 이를 U와 V로 분리하는 것을 말한다.
실수나 복소수로 이루어진 원소로 구성되는 m * n 행렬 M은 다음과 같은 3개 행렬의 곱으로 분해할 수 있다.
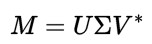
U는 m*m의 크기를 갖는 직교행렬을 의미하고, Σ 는 m*m의 크기를 가지는 대각행렬이고, V는 n*n의 유니터리 행렬을 나타낸다.
Figure 5 SVD
여기서 중요한 사항은 행렬 U는 MM^T, V는 M^T M의 고유벡터(eigenvector)를 각각 포함하고 있다는 점이다.
행렬 V가M^T M의 고유벡터를 가지고 있다는 것의 의미는 해당 행렬이 row space에 대한 차원축소를 실행한 것이고, 이는 곧 item-item 상관관계에 대한 고유치를 가지고 있다는 것으로 해석할 수 있다.
행렬 UΣ 는 원래의 평점행렬을 행렬 V에 대한 관계로 변형한 것으로 이야기 할 수 있다.
이와 같이 생각하면 SVD는 원래 사용자와 아이템의 관계를 일반적인 2차원의 직교좌표계를 이용해 표현했던 것을 사용자와 아이템에 대한 고유치를 계산하고, 계산된 고유치를 이용해 기존의 평점데이터로 다시 표현한 것이다.
위의 SVD그림에 빗대어 설명하면 σ_1 과 σ_2 는 기존의 데이터를UΣ 행렬과 V 행렬을 이용해 새로운 좌표계를 만들고 이것을 기준으로 기존의 데이터를 변형해 나타낸 것으로 이해할 수 있다.
데이터를 SVD형태로 나타내게 되면 차원축소의 이점으로 데이터가 작아지는 것과 더불어 노이즈제거에도 효과적이다. 데이터를 새롭게 설정된 좌표계에서 표현할 때 다른 값들과의 차이가 크다면 그만큼 노이즈일 가능성이 크다고 생각할 수 있다. 왜냐하면 새롭게 구축된 좌표계는 사용자와 아이템의 고유값을 계산한 것이기 때문이다.
평가방법
Collaborative Filtering을 이용해 추천시스템을 개발했다면 해당 시스템의 성능을 평가해야 한다.
평가를 위한 방법은 크게 다음과 같은 3가지로 나누어 볼 수 있다.
- 사용자 평가
- 온라인 평가
- 오프라인 평가
사용자평가와 온라인 평가는 사용자에 의한 평가라는 공통점을 가지고 있다. 이 둘의 가장 큰 차이는 추천시스템의 평가를 위해 어느 시점에 사용자를 활용하는가에 있다.
사용자 평가는 특정한 시점에 사용자를 초청해 추천시스템의 성능을 점검해보는 것이고 온라인평가는 추천시스템이 실제 환경에서 활용되고 있는 상황에서 사용자가 보여주는 행위를 보고 성능을 평가하는 방식이다.
오프라인 평가는 과거의 데이터를 이용해 평가하는 방식으로 데이터 기반의 평가이기 때문에 사용자를 초청할 필요가 없다.
사용자평가
사용자평가에서는 사용자를 초청하고 추천시스템을 사용하도록 요구한다. 그리고 사용자들로부터 피드백을 받는다. 피드백의 반응이 좋으면 성능이 좋은 추천시스템으로 평가하는 방식이다.
사용자평가의 최대 장점은 평가를 위해 초청한 사용자들에게 원하는 정보를 물어보고, 수집할 수 있다는 점이다. 단순하게는 추천시스템에 대한 선호도를 물어볼 수 있고, 온라인평가에서는 알기 어려운 사용상의 문제점, 추천의 적합도에 이유등을 자유롭게 물어볼 수 있다.
사용자평가는 초청된 사용자가 추천시스템을 평가하기 위해 왔다는 것을 인지하고 있기 때문에 100% 자신의 의사를 명확하게 표현하기 어려울 수도 있고, 환경적인 요소로 인해 왜곡된 대답을 할 수도 있다는 점을 인지해 추천시스템의 최종적인 평가를 해야 한다.
온라인평가
온라인평가는 사용자를 별도로 초청하지 않고, 실제 환경등에 추천시스템을 적용하고, 사용자의 행위를 보고, 추천시스템의 성능을 파악하는 방식이다.
이 방식은 사용자가 추천시스템 평가를 하고 있다는 사실을 인지하고 있지 않기때문에 사용자평가에서 발생할 수 있는 문제인 왜곡이 발생하지 않는 장점이 있다.
온라인평가에서는 A/B 테스팅을 이용해 추천시스템의 성능을 평가한다.
예를 들어 추천시스템을 적용하지 않은 경우와 적용한 경우의 2 상황을 무작위적으로 사용자에게 보여주고, 이 둘의 결과를 비교하는 방식이다.
만약 추천시스템을 적용하지 않은 상황에서의 CTR(Click Through Rate)가 10%였고, 적용했을때 CTR이 20%였다면 추천시스템이 기존대비 성능이 좋다고 평가하는 방식이다.
이를 좀더 구체적으로 표현하면 다음과 같다.
1. 사용자그룹을 2개의 그룹 A와 B로 나눈다.
2. 그룹A에는 추천시스템을 적용하지 않고, 그룹B에만 추천시스템을 적용한다.(혹은 그 반대로 시행한다)
3. 일정시간이 지난 후에 그룹 A/B의 CTR과 같은 수치를 비교한다.
이 방식은 의료계에서 신약의 효과를 측정하기 위해 사용하는 방법과 매우 유사하다.
보다 정확한 평가를 위해서 동일한 사용자에게 추천시스템을 활용하는 경우와 그렇지 않은 경우를 모두 시험하는 경우도 있다.
오프라인평가
오프라인평가에서는 추천시스템의 성능을 평가하기 위해 과거의 데이터를 이용한다.
예를 들어 앞서 설명한 Netflix Prize Contest가 오프라인평가의 가장 대표적이다.
참가자들이 추천시스템을 만들고, 해당 시스템에 과거의 데이터를 넣어서 얼마나 정확하게 예측하는지를 평가한다.
오프라인평가는 평가방법과 평가항목을 표준화시킬 수 있기 때문에 추천시스템 평가에서 자주 활용된다.
평가항목은 Accuracy, Coverage, Confidence, Novelty등 다양한 항목들이 있다.
마치며
본고에서는 추천시스템의 기본적이며 가장 핵심적인 기술인 Collaborative Filtering에 대해 설명하였다.
Collaborative Filtering은 제안된지 20년이 지난 기술이지만 그 간결함과 성능으로 인해 아직도 많은 추천시스템에서 활용하고 있다.
많은 변형 알고리즘과 방법들이 소개되었으며 별도의 메타데이터가 없어도 잘 동작한다는 점은 Collaborative Filtering의 장점이라고 할 수 있다.
하지만 데이터가 적은 경우(Cold Start & Data Sparsity)에는 효과를 보여주기 어렵고, Scalability 문제가 있다는 점 그리고 모든 도메인에 적용하기는 어렵다는 것은 Collaborative Filtering의 대표적인 단점으로 꼽힌다.
많은 연구자들과 기업에서 Collaborative Filtering을 연구하고 있기 때문에 앞으로 더욱 발전된 방법들이 우리 앞에 나타날 것이고, 국내에서도 이에 못지 않은 많은 관련연구가 활성화되기를 기원한다.
Reference
Recommender Systems, Charu Aggarwal, Springer
https://en.wikipedia.org/wiki/Singular_value_decomposition
http://techblog.netflix.com/2015/04/learning-personalized-homepage.html
Metadata Embedding for User and Item Cold-start Recommendations, Maciej Kula
집단지성 프로그래밍, 토비세가란, 한빛미디어
Building Machine Learning System with python, Packt
/필/자/소/개/

안명호 |(주)DeepNumbers 대표이사, http://www.deepnumbers.com, james@deepnumbers.comv
앞으로 소프트웨어에서 머신러닝이 핵심적인 역할을 할 것이라는 믿음을 가지고
DeepNmbers에서 머신러닝을 이용한 서비스 개발에 매진하고 있으며, 머신러닝에 관련된 것이라면 무엇이든 왕성한 호기심을 가지고 있다.
 |
공개SW역량프라자에 의해 작성된 이 저작물은 크리에이티브 커먼즈 저작자표시-변경금지 4.0 국제 라이선스에 따라 이용할 수 있습니다. |

| 번호 | 제목 | 작성 | 조회수 |
|---|---|---|---|
| 19 | [OpenFOAM] OpenFOAM 설정파일 형식 (OpenFOAM 기본) | 2016-10-28 | 1896 |
| 18 | [OpenFOAM] OpenFOAM 개요 및 기본 (OpenFOAM 기본) | 2016-10-14 | 3543 |
| 17 | [IT열쇳말] 자바스크립트 | 2016-10-11 | 2376 |
| 16 | Collaborative Filtering - 추천시스템의 핵심기술 | 2016-09-27 | 6768 |
| 15 | [IT열쇳말] 이클립스 | 2016-08-19 | 3130 |
| 14 | [IT열쇳말] 챗봇 | 2016-08-05 | 1895 |
| 13 | [IT열쇳말] 젯브레인 | 2016-07-29 | 1819 |
| 12 | [OpenFOAM] OpenFOAM이란 (OpenFOAM 시작하기) | 2016-07-25 | 10369 |
| 11 | ‘시타라(Sitara)’ 프로세서에서의 ‘이더캣(EtherCAT)’ | 2016-07-12 | 2124 |
| 10 | 오픈소스로 개발 실력 쌓기 | 2016-07-06 | 1427 |
0개 댓글