


<COVER STORY 5>

클라우드를 위한 오픈소스
클라우드 구성을 위한 레이아웃 및 오픈소스
클라우드는 하나의 소프트웨어로만 구성되지 않는다. 클라우드를 구성하기 위해서는 각 계층별로 필요한 소프트웨어가 조합되야 한다.
이 글을 통해 각 계층별로 어떠한 오픈소스들이 존재하고 그 각각은 어떤 특징을 가지고 있는지 알아보자.
클라우드의 분류는 사용자가 제공 받는 서비스에 따라 달라질 수 있다.
◆ 클라우드의 분류
우선 사용자가 제공 받는 서비스에 따라 클라우드를 분류하면 IaaS(Infra as a Service), PaaS(Platform as a Service), SaaS(Software as a Service)로 나뉜다. 각 서비스에 대해 간략히 소개하면 다음과 같다.
- IaaS : 사용자가 인프라(Infra)를 제공받는 서비스다. 컴퓨팅 자원, 스토리지 자원, 데이터베이스 자원 등을 사용자가 원하는 만큼 제공받을 수 있고, 사용한 만큼 비용을 지불하는 서비스다.
대표적인 예로는 KT의 유클라우드(http://www.olleh.com/index.asp?code=BAA00), 아마존의 아마존 웹 서비스(http://aws.amazon.com/)를 들 수 있다.
- PaaS : 사용자가 애플리케이션이나 서비스를 실행할 수 있는 플랫폼 형태의 서비스를 제공받을 수 있다. 사용자는 인프라 위에 올라와 있는 플랫폼에 따라 서비스를 선택할 수 있고, 역시 사용한 만큼 비용을 지불한다. 대표적인 예로는 파이썬 런타임, 자바 런타임 플랫폼 등을 지원하는 구글의 앱엔진(http://code.google.com/intl/ko/appengine/)을 들 수 있다.
- SaaS : 사용자가 서비스 제공자가 지원하는 소프트웨어들을 제공받는 서비스다. 일반적인 사용자들이 많이 사용하고 있고, 대부분을 무료로 사용할 수 있다. 대표적인 예로는 네이버의 N드라이브(http://ndrive.naver.com/index.nhn), 구글의 지메일(http://www.gmail.com), 구글 앱스(http://www.google.com/apps/intl/ko/business/index.html)를 들 수 있다.
위 세 가지 분류 중에서 오픈소스를 이용해 만들 수 있는 서비스는 IaaS다. PaaS나 SaaS는 아직 한국에서 많이 활성화되지 않았지만 IaaS는 KT의 유클라우드와 아마존의 AWS(Amazon Web Service)를 통해 많이 알려지고 사용되고 있다. 이 글을 통해 실제로 어떤 오픈소스들이 사용되고 있고, 어떻게 IaaS를 구축할 수 있는지를 자세히 알아보자.
◆ IaaS 구성 계층
IaaS는 하나의 소프트웨어만으로 이뤄지지 않으므로 여러 계층을 통해 하나의 시스템으로 구성하는 것이 일반적이다. 하나의 시스템이므로 하나의 서버에 구축할 수도 있지만 보통 다수의 서버들을 계층별로 나눠 제공할 수도 있다. 각 계층은 컴퓨팅 클라우드, 스토리지 클라우드, 데이터 클라우드 그리고 클라우드 관리로 나눌 수 있다. 각 계층에 대한 정의와 사용되는 오픈소스에 대해 간단히 살펴보자.
컴퓨팅 클라우드
서버의 컴퓨팅 자원을 나눠 제공하는 계층이다. 즉, 서버에 존재하는 자원인 CPU, 램, 디스크 등을 사용자가 필요한 만큼 할당하고, 상황에 따라 자원을 늘이고 줄일 수 있는 계층이다.
[오픈소스]
젠(http://xen.org/)
KVM(http://www.linux-kvm.org/page/Main_Page)
스토리지 클라우드
서버에 존재하는 스토리지 자원을 나누거나 통합해 제공하는 계층이다. 서버에 큰 스토리지가 존재하면 그 스토리지 자원 일부를 사용자에게 할당해 주거나 더 큰 스토리지가 필요하다고 하면 여러 서버에 있는 자원을 통합해 수 PB의 용량을 제공해 주는 계층이다.
[오픈소스]
하둡 분산 파일시스템(http://hadoop.apache.org/)
글러스터 파일시스템(http://www.gluster.com/)
섹터 파일시스템(http://sector.sourceforge.net/)
데이터 클라우드
서버에 존재하는 데이터베이스 자원을 제공하는 계층이다. 하나의 서버에 존재하는 데이터베이스 자원을 나눠 제공하거나 여러 서버에 존재하는 데이터베이스 자원을 통합해 하나의 큰 데이터베이스를 구축할 수 있도록 제공하는 계층이다.
[오픈소스]
카산드라(http://cassandra.apache.org/)
몽고디비(http://www.mongodb.org/)
HBase(http://hbase.apache.org/)
클라우드 관리
여러 서버들에 존재하는 데이터들을 분산해서 관리할 수 있는 방법을 제공하는 계층이다. 이 계층은 각 계층을 쉽게 관리할 수 있도록 관리, 로그 데이터 분석 등을 제공한다.
[오픈소스]
립버트(http://libvirt.org/)
주키퍼(http://zookeeper.apache.org/)
척와(http://incubator.apache.org/chukwa/)
◆ 클라우드 구성을 위한 계층별 오픈소스
그럼 클라우드를 직접 구축하기 위해 각 계층별로 많이 사용되는 오픈소스 소프트웨어들을 비교해 보자.
◆ 컴퓨팅 클라우드
컴퓨팅 클라우드는 가상화와 밀접한 관련을 가지고 있는 계층이다. 가상화란 하이퍼바이저(Hypervisor)라고 하는 가상 머신 모니터(Virtual Machine Monitor)를 이용해 하나의 서버에서 여러 개의 운영체제를 동작시킬 수 있는 기술을 의미한다.
가상화 관련 기술을 이용해 주목받고 있는 상용 제품의 예로는 VM웨어의 브이스피어(V-sphere), 시트릭스의 젠 서버(Xen Server) 그리고 국내 제품으로 아헴스의 아헤모스(AhemoS) 등이 있고, 유명 서비스의 예로는 아마존의 EC2와 KT의 유클라우드(UCloud) CS가 있다. 그럼 컴퓨팅 클라우드를 직접 구축할 수 있고 기술 발전에 기여한 오픈소스인 젠과 KVM에 대해 알아보자.
젠
젠은 1990년 후반 캠브리지 대학의 제노서버 프로젝트에 의해 만들어졌고 2002년에 오픈소스화됐다. 그럼 젠의 아키텍처는 어떤 모습일까? 젠은 하이퍼바이저와 도메인 0, 도메인 N으로 구성된다. 하이퍼바이저는 하나의 물리적 머신 위에 여러 개의 가상 머신을 실행하는 중심 소프트웨어로, 가상 머신 모니터(VMM)라고 불리기도 한다. 그리고 도메인 0은 특권을 가지고 있는 도메인으로서, 실제 가상 머신으로 사용되는 도메인 N들을 생성 및 관리할 수 있다. 전체 아키텍처는 <그림 1>과 같다.
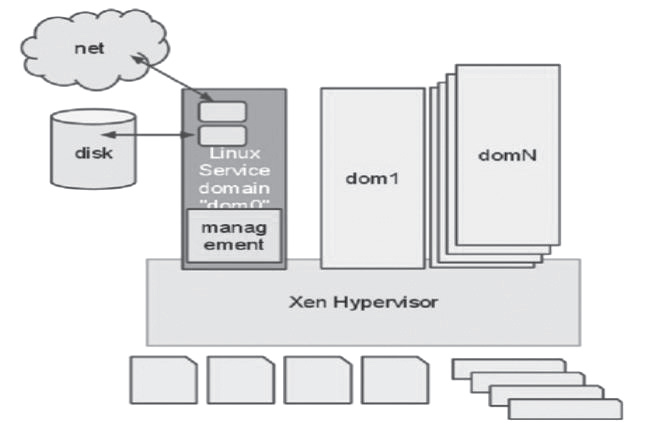
<그림 1> 젠 아키텍처(http://www.xen.org/file/Marketing/WhyXen.pdf)
젠의 특징을 살펴보면 다음과 같다.
● 가벼운 하이퍼바이저 모델(Thin Hypervisor Model)
시스템의 가장 높은 권한을 가진 하이퍼바이저가 가볍게 구성되어 있으므로 성능과 보안 문제 해결에 조금 더 쉽게 접근할 수 있다. 젠 하이퍼바이저가 가벼운 이유는 많은 양의 코드 및 관리 기능을 가진 부분을 도메인 0이 가지고 있기 때문이다.
● 운영체제 중립적 사용 가능
도메인 0에서 사용할 수 있는 운영체제는 제한을 가지고 있지 않다. 리눅스, 솔라리스뿐만 아니라 다양한 운영체제들을 탑재해 동작시킬 수 있으므로 운영체제의 유연성을 제공한다.
● 보안 문제 해결의 용이성
젠은 하이퍼바이저가 모든 가상 머신들을 격리시켜 관리하기 때문에 보안 문제를 해결하기 쉽고, 앞서 이야기한대로 하이퍼바이저가 가볍게 구축됐으므로 보안 문제의 확인이 쉽고 빠르다.
● 가상화 기술의 다양화
젠은 전가상화(Full Virtualization)와 반가상화(Para Virtualization)를 모두 지원한다. 반가상화의 경우 게스트 운영체제와 하이퍼바이저의 소통을 최소화할 뿐 아니라 도메인 0을 거치지 않고 I/O를 수행할 수 있는 패스-쓰루 기술을 이용해 최적의 성능을 낼 수 있다.
이와 같은 특징을 가진 젠은 현재 시스코, 시트릭스, 후지쯔, 레노버, 노벨, 오라클, 삼성에서도 각자의 솔루션으로 이용하고 있고, 심지어 퍼블릭 클라우드를 제공하는 아마존, 클라우드닷컴(Cloud.com), 고그리드(GoGrid), KT에서도 젠을 이용해 서비스할 정도로 믿을 수 있는 성능과 안정성을 제공하고 있다. 젠을 이용한 컴퓨팅 클라우드의 구축은 http://xen.org/에서 다운로드해 설치할 수 있다.
KVM
KVM은 래드헷 주도로 개발하고 있는 가상화 오픈소스로, 젠과 VM웨어의 브이스피어와 함께 가상화 기술의 큰 축으로 알려져 있다. KVM은 운영체제 커널을 이용해 가상 머신 환경을 구축하는 방법을 이용한다. 즉, 커널이 하이퍼바이저 역할을 한다.
젠의 하이퍼바이저 역할을 KVM은 리눅스 커널이 담당하므로 하이퍼바이저 기능을 수행하면서 리눅스 커널의 오버헤드가 생길 수 있다. KVM을 이용하고 싶은 독자는 http://www.linuxkvm.org/page/Main_Page에서 다운로드해 설치할 수 있다.
◆ 스토리지 클라우드
스토리지 클라우드는 파일시스템과 밀접한 관련을 가지고 있는 계층이다. 하나 이상의 서버를 묶어 하나의 스토리지를 제공하는 파일시스템을 의미한다. 구글의 구글 파일시스템과 아마존의 S3 등이 주목받으면서 많은 연구가 진행됐다. 이러한 파일시스템들이‘분산 파일시스템’이라고 불리면서 IaaS의 한 축으로 발전하고 있다. 다양한 종류의 분산 파일시스템의 공통적인 특징은 다음과 같다.
- 여러 개의 서버에 존재하는 스토리지를 하나로 묶어 하나의 글로벌 네임스페이스를 제공
- 고장 방지 및 성능 향상을 위해 하나의 데이터를 다른 서버들에 여러 개 복제
- 파일시스템의 메타데이터를 저장하는 서버와 실제 파일을 저장하는 서버를 분리해 관리
- 파일시스템 크기의 동적 변화 가능
- 기존 파일시스템에 존재하는 읽기∙쓰기 연산을 제공하면서 파일시스템에 접근할 수 있는 API 제공
그럼 이제 스토리지 클라우드 오픈소스로 많이 사용되는 하둡(Hadoop) 분산 파일시스템과 섹터 파일시스템에 대해 알아보자.
하둡
하둡 분산 파일시스템은 구글 파일시스템의 클론으로서 현재 아파치 프로젝트인 하둡의 일부이고 아파치 오픈소스 라이선스 정책을 이용하고 있다. 하둡 프로젝트는 여러 개의 서브 프로젝트로 구성되어 있는데, 공통 모듈을 관리하는 하둡 커먼(Hadoop Common)과 하둡 분산 파일시스템(Hadoop Distributed File System), 하둡 맵 리듀스(Hadoop MapReduce) 등의 서브 프로젝트가 그것들이다.
야후는 하둡 분산 파일시스템 개발에 크게 기여했고 현재 자사의 서비스에 적용하고 있다. 2010년 발표된 논문에 의하면 야후에서는 2만5,000개의 서버를 이용해 25PB를 응용프로그램 데이터를 저장하는 데 사용하고 있다. 2만5,000개의 서버는 하나의 클러스터로 구성된 것이 아닌, 여러 개의 클러스터로 구성되어있고 가장 큰 클러스터는 3,500개의 서버를 하나로 묶어 사용하고 있다.
하둡 분산 파일시스템은 네임 노드, 데이터 노드로 구성된다.
네임 노드는 디렉터리와 파일의 구조 정보를 가지고 있고 해당 디렉터리와 파일이 저장되어 있는 데이터 노드 정보를 가지고 있다. 데이터 노드는 실제로 사용자에 의해 업로드된 데이터들을 가지고 있다. 전체적인 구조도는 <그림 2>와 같다.
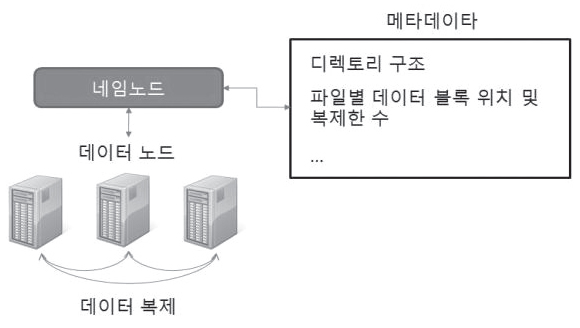
<그림 2> 하둡 분산 파일시스템 아키텍처
네임 노드는 전체 파일시스템에 대한 메타데이터를 관리한다.
디렉터리와 파일에 대한 구성뿐만 아니라 각 데이터들이 어느 위치에 존재하고 몇 개의 데이터가 복사되어 있는지에 대한 정보를 포함하고 있다. 그리고 하나 존재하는 네임 노드는 모든 데이터를 메모리에 저장한다. 만약 문제가 생기면 재구동의 문제가 있으므로 체크포인트 노드에 네임 노드에서 보유하고 있는 일부의 정보를 복사해서 예상되는 문제를 방지하고 있다.
데이터 노드에 저장된 파일은 블록 단위로 구성되어 있고, 여러 개의 데이터 노드에 동일한 파일이 복제된다. 파일은 디폴트로 128MB 단위의 블록으로 나뉘게 되고, 세 개의 데이터 노드에 복제된다. 예를 들어 320MB의 파일을 업로드하는 경우, 128MB 두 개의 파일과 64MB 한 개의 파일로 나누어 관리된다. 그리고 각 블록들이 세 개의 데이터 노드에 존재하게 된다.
하둡 분산 파일시스템을 설치하기 위해서는 한 개 이상의 리눅스 서버가 필요하다. 그리고 하둡 분산 파일시스템은 자바로 개발됐으므로 Java 1.6.x 버전(현재 최신버전)이 설치되어 있어야 한다. 하둡은 로컬 모드, 수도 분산 모드, 완전 분산 모드 세 가지로 구동시킬 수 있다.
자세한 설치 방법 및 설정 파일 변경에 대한 내용은 하둡 분산 파일시스템의 싱글 노드 설정(http://hadoop.apache.org/common/docs/current/single_node_setup.html)과 클러스터 설정(http://hadoop.apache.org/common/docs/current/cluster_setup.html)을 참고하길 바란다.
섹터 파일시스템
하둡 이외에 스토리지 클라우드를 구성할 수 있는 분산 파일시스템으로 섹터 파일시스템이 있다. 섹터 파일시스템은 2006년 미국 일리노이대학에서 개발했고 BSD 라이선스 정책을 이용하고 있다.
섹터 파일시스템은 상업적인 목적으로 이용되진 않지만 굉장히 크기가 큰 과학적 데이터 전송 및 분석에 많이 사용된다. 특히 100TB 이상의 데이터를 미국에서 한국의 카이스트까지 아무런 문제없이 매우 빠른 속도로 전송해 안전성을 검증받은 이후 더 많은 관심을 받고 있는 파일시스템이다.
섹터 파일시스템은 하둡과 비슷한 구조를 가지고 있지만 몇가지 차이점이 있다.
- 언어 : 하둡은 자바로 구현됐지만 섹터 파일시스템은 C++로 구현됐다. 이처럼 실행이 더 빠른 언어를 적용함으로써 많은 사용자들이 몰리는 노드를 신속히 처리할 수 있다는 장점이 있다.
- 파일 보관 방법 : 하둡은 파일을 고정 크기의 블록으로 나눠 관리하지만 섹터 파일시스템은 파일을 분할하지 않고 서버의 파일시스템을 그대로 사용한다. 이 방법에는 장단점이 있다. 우선 장점은 파일을 분할하지 않고 기존 시스템의 파일시스템을 그대로 사용하므로 전체 시스템의 디자인이 단순하게 구성된다. 또한 데이터가 저장된 노드의 디렉터리를 간단히 스캔해 메타데이타 정보를 빠르게 구축할 수 있으며 데이터가 전달된 하나의 노드에만 접근해 데이터를 전달받을 수 있는 장점이 있다.
반면 섹터 파일시스템의 파일 보관 방법은 기존 시스템의 파일시스템이 저장할 수 없는 크기의 데이터는 분할해서 보관해야 하는 단점이 있다.
섹터 파일시스템은 하둡 분산 파일시스템과 비슷한 구조를 가지고 있다. 전반적인 구조는 섹터 파일시스템 홈페이지(http://sector.sourceforge.net/tech.html)에서 확인할 수 있다.
이상 스토리지 클라우드인 하둡 분산 파일시스템과 섹터 파일 시스템에 대해 살펴봤다. 하지만 여기서 짧게 소개한 시스템 이외에도 굉장히 많은 스토리지 클라우드에 이용되는 분산 파일시스템들이 있다. 관심 있는 독자들은 위키 페이지(http://en.wikipedia.org/wiki/List_of_file_systems#Distributed_file_systems)에서 Distributed File System 부분을 참고하길 바란다.
◆ 데이터 클라우드
데이터 클라우드는 기존의 데이터베이스를 대체할 수 있는 계층이다. 데이터베이스는 데이터를 저장하기 위한 용도로 많이 사용되지만 최근 인터넷의 데이터가 급증하면서 기존의 관계형 데이터베이스(RDBMS)로는 저장 및 운영하기가 어려워졌고, 이를 해결하기 위해 새로운 형태의 데이터 저장소가 요구됐다. 따라서 오픈소스는 아니지만 구글의 빅테이블, 아마존의 다이나모와 같은 새로운 형태의 데이터 저장소가 개발됐고, 이러한 새로운 저장소들을 NoSQL이라고 부르며 많은 연구가 진행되고 있다. 기존에 개발된 많은 데이터 클라우드의 공통적인 특징을 보면 다음과 같다.
- 키와 값(Key-value)을 쌍으로 저장하고 키-값을 이용한 데이터 모델 적용
- 값싼 하드웨어를 이용해 데이터들을 분산해 저장
- 데이터 저장소들을 쉽게 증가시킬 수 있음.
- 대규모 데이터를 빠르게 처리하기 위한 빠른 인덱싱 제공
그럼 실제 많이 사용되는 다음 커뮤니케이션의 아고라에 적용된 몽고 디비와 페이스북의 인박스 서치에 사용되는 카산드라에 대해 조금 더 자세히 살펴보자.
몽고 디비
몽고 디비는 10gen에서 2007년부터 개발된 오픈소스 프로그램이다. 문서기반의 데이터 저장소로서 키-값을 이용한 데이터 모델의 쿼리가 어렵다는 점과 여러 서버를 통해 큰 데이터 저장소를 만들기 위한 확장성을 고려해 제작됐다.
그리고 리눅스뿐만 아니라 윈도우, OS X, 솔라리스에서 사용될 수 있도록 다양한 플랫폼을 지원한다. 몽고 디비는 다음과 같은 특징을 가진다.
● 문서 기반
동적 타입으로 스키마 변화가 용이하고 높은 성능과 쉬운 확장성을 위해 조인과 트랜잭션이 없다.
● 높은 성능
조인과 트랜잭션이 없으므로 읽기∙쓰기가 빠르고 비동기 쓰기를 지원해 빠른 성능을 제공한다.
● 가용성
마스터 서버에 문제가 발생해도 슬레이브에 미리 데이터를 복제해 둠으로써 항상 문제없이 사용할 수 있다.
● 확장성
데이터들은 여러 개의 서버에 복제되고 쉽게 서버를 추가할 수 있다. 샤드(Shard)라는 기술을 이용해 자동으로 여러 서버에 파티션된 데이터를 분산할 수 있다.
몽고 디비의 구조는 여러 대의 샤드 서버와 설정 서버, 라우터 서버로 구성된다. <그림 3>을 통해 전체적인 구조를 알 수 있다.
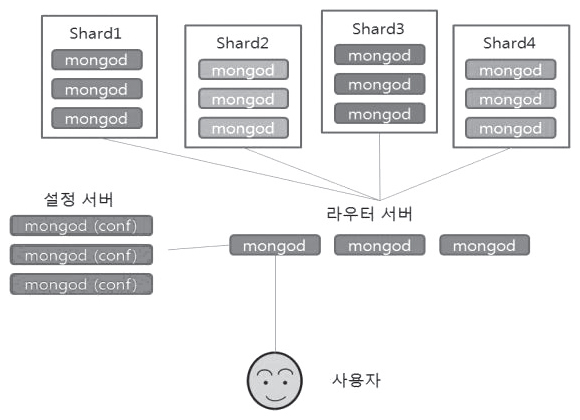
<그림 3> 몽고 디비의 샤드와 설정 서버, 라우터 서버의 관계
샤드 서버는 전체 데이터에서 특정 파티션을 맡아 여러 대의 서버에 데이터를 복제해 둠으로써 데이터의 안전성을 지원한다.
샤드 서버는 하나 이상의 서버들로 구성되어 동일한 데이터들의 복제본을 가지고 있는데, 동작하는 방식은 주로 프라이머리-세컨더리 구조로 동작한다. 이 구조는 모든 데이터들은 서버에 복제되지만 특정 서버가 프라이머리로 지정되고 이 서버는 쓰기 요청을 처리한다. 세컨더리는 복사본을 가지고 있어서 읽기 요청을 처리할 수 있지만 쓰기 요청을 처리할 수 없다.
설정 서버는 데이터들이 어떤 샤드에 존재하는지와 샤드 서버 관련 정보 등을 메타데이터를 통해 관리하고 있다. 보통 1~3대의 서버를 통해 관리되며 모든 설정 서버에는 동일한 데이터들이 저장된다.
라우터 서버는 사용자의 요청을 받아 설정 서버로부터 어느 샤드에 있는지 정보를 얻고 실제 해당 샤드로부터 데이터를 클라이언트에게 전달하는 역할을 한다. 다운로드 및 설치는 몽고 디비 홈페이지(http://www.mongodb.org/)를 통해 진행할 수 있다.
카산드라
카산드라는 페이스북에서 개발된 오픈소스이고, 아파치 오픈소스(http://cassandra.apache.org/)로 관리되고 있다. 카산드라는 아마존의 키-값 저장소인 다이나모의 완전 분산 디자인 정책과 구글 빅테이블의 컬럼패밀리 기반의 데이터 모델을 이용해 개발됐다.
카산드라의 구조는 매우 간단하다. 카산드라는 크게 로드밸런서 또는 네이밍 서버를 가지고 있고 나머지는 노드로 구성된다. 전체 구조는 <그림 4>를 보면 알 수 있다.
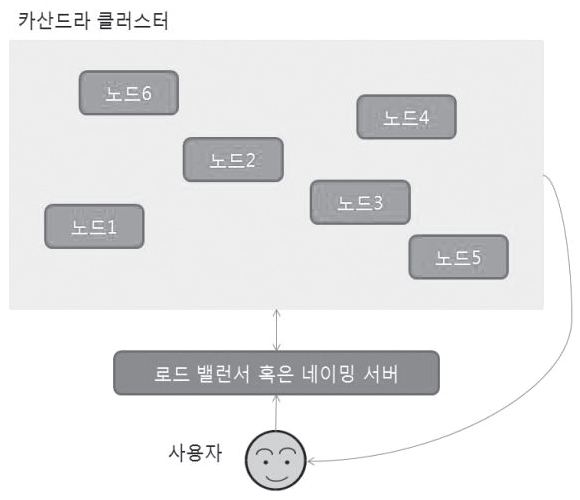
<그림 4> 카산드라의 노드와 로드 밸런서, 네이밍 서버를 이용한 구조
카산드라에서는 몽고 디비에서 메타데이터들을 저장하고 있는 설정 서버가 존재하지 않는다. 대신 다이나모에서 사용하는 강력한 해시 알고리즘인 일관적인 해시를 이용해 실제 데이터를 저장하고 있는 노드를 쉽게 찾을 수 있으며, 노드의 장애 복구 및 동적 추가를 쉽게 구현할 수 있다(D. Karger의 논문 <Consistent hashing and random trees: Distributed caching protocols for relieving hot spots on the World Wide Web> 참고).
카산드라에서는 몽고 디비에 있는 라우터 서버 대신 로드밸런서나 네이밍 서버를 이용해서 구축한다. 로드 밸런서 혹은 네이밍 서버가 사용자의 요청을 받으면 카산드라 클러스터에 존재하는 특정 노드에 해당 요청을 전달하고, 전달 받은 노드는 일관적인 해시를 이용해 데이터가 저장된 노드를 찾아 사용자에게 원하는 데이터를 전달해 준다.
◆ 클라우드 관리
클라우드 관리는 앞서 이야기한 세 가지 클라우드를 효율적으로 관리하거나 이용해 데이터를 분석할 수 있는 방법들을 제공한다. 그래서 앞서 설명한 프로젝트들의 서브 프로젝트로 진행되거나 공통적으로 제공하는 인터페이스를 이용해 다양한 프로젝트를 지원하도록 설계된다.
클라우드 관리 프로젝트 중 컴퓨팅 클라우드의 하이퍼바이저 종류에 상관없이 원격에서 도메인을 관리할 수 있는 라이브러리인 립버트(Libvirt)에 대해 알아보자.
립버트
립버트는 2005년부터 레드햇 주도로 개발된 오픈소스이고, 매달 새로운 릴리즈가 나올 정도로 활발히 개발되고 있다. 립버트는 가상 머신 관리, 스토리지 관리, 네트워크 인터페이스 관리 등의 기능을 제공하며, 마이크로소프트의 하이퍼바이저를 제외한 대부분의 하이퍼바이저를 지원하고 있다. 립버트의 주요 기능은 다음과 같다.
● 가상 머신 관리
가상 머신의 동작을 위한 시작, 정지, 일시정지, 마이그레이션 및 디스크, 네트워크 인터페이스, CPU의 핫 플러깅 등을 제공한다.
● 저장 공간 관리
다양한 포맷(qcow2, vmdk, raw 등)의 가상 머신 이미지 생성, 가상 머신에 할당해 주는 공간인 LVM 볼륨 그룹 열거와 새로운 LVM 볼륨 그룹 및 논리 볼륨 생성, 디스크 파티션 관리 등의 기능을 제공한다.
● 네트워크 관리
물리적, 논리적 네트워크 인터페이스 관리 기능을 제공한다.
예를 들어 인터페이스 열거 및 설정, 브릿지 설정 등의 기능을 제공한다.
● 가상 네트워크 관리
NAT를 이용한 가상 네트워크 생성 및 관리 기능, 방화벽 및 라우터 기능을 제공한다.
립버트의 기능과 클라우드 관리 툴을 간단히 살펴봤다. 직접 클라우드를 구축할 때 다양한 기능들을 제공하는 클라우드 관리툴을 적극 이용하길 권한다.
◆ 오픈소스를 통한 재창조
이 글을 통해 요즘 주목받는 클라우드와 그 기반을 이루는 오픈소스에 대해 설명했다. 이를 계기로 독자들이 클라우드와 관련된 오픈소스에 대해 조금 더 쉽게 느끼고 가깝게 다가갈 수 있길 희망한다.
사실 많은 사람들이 오픈소스에 대해 상용화하기 어렵고 제대로 동작하지 않는 것들이 많다고 생각하지만 현재의 클라우드 제품들은 많은 오픈소스들을 이용해 재창조된 것들이 많다. 필자가 클라우드를 접하면서 새삼 느낀 바이지만 강력하면서도 높은 완성도를 제공하는 오픈소스들이 다수 존재하고 우리가 사용하는 다양한 것에 반영되어 우리 생활을 편리하게 해 주고 있다. 이 글을 통해 독자들도 오픈소스에 많은 관심을 갖고 참여해 기량을 뽐낼 수 있었으면 한다.
/필/자/소/개/

박윤성 | parkys1@gmail.com
삼성 소프트웨어멤버십 정회원으로 활동했고, 한국과학기술원(KAIST)에서 로봇공학 석사학위를 취득했다. 현재는 한국의 클라우드 컴퓨팅 기업 ‘아헴스(http://www.ahems.co.kr)’에서 토종 클라우드 솔루션 개발을 위해 노력하고 있다.
※ 본 내용은 (주)마소인터렉티브(http://www.imaso.co.kr/)의 저작권 동의에 의해 공유되고 있습니다.
Copyright ⓒ Maso Interactive Corp. 무단전재 및 재배포 금지

| 번호 | 제목 | 작성 | 조회수 |
|---|---|---|---|
| 8 | [구글 앱 엔진] 구글 앱 엔진 XMPP 활용해 안드로이드 푸시 서비스 구현Ⅱ | 2013-10-28 | 1833 |
| 7 | [구글 앱 엔진] 구글 앱 엔진 XMPP 활용해 안드로이드 푸시 서비스 구현Ⅰ | 2013-10-17 | 2232 |
| 6 | [클라우드] 클라우드 핵심 기술 ‘하둡(Hadoop)’ 은 무슨 뜻일까 | 2013-07-10 | 2013 |
| 5 | [클라우드] 클라우드 구성을 위한 레이아웃 및 오픈소스 | 2013-04-26 | 1827 |
| 4 | [클라우드] N스크린 시대를 준비하는 개발자의 자세, 지피지기면 백전백승 N스크린 | 2013-04-11 | 1556 |
| 3 | [클라우드] 서비스 in the 클라우드, 이벤트 급증에 대한 트래픽 분산 사례 | 2013-04-05 | 1749 |
| 2 | [클라우드] 모바일을 위한 클라우드, 모바일 클라우드의 태동 | 2013-03-26 | 2230 |
| 1 | [클라우드] 클라우드 컴퓨팅의 진화로 보는 클라우드 서비스의 오늘과 내일 그리고 국내 현주소 | 2013-03-11 | 3107 |
0개 댓글