


Martin Heller, Andrew C. Oliver, Ian Pointer | InfoWorld / 2018-10-05
요즘 세상에 데이터보다 더 중요한 것은 없다. 우리는 어느 때보다 더 많은 데이터를 가지고 있고, 이를 저장하고 분석할 방밥도 어느 때보다 많이 가지고 있다. 예컨대 SQL 데이터베이스, NoSQL 데이터베이스, 분산 OLTP 데이터베이스, 분산 OLAP 플랫폼, 분산 하이브리드 OLTP/OLAP 플랫폼 등이다. 2018년 최괴의 오픈소스 소프트웨어 대상 데이터베이스 및 데이터 애널리틱스 플랫폼 부문에는 스트림 프로세싱의 혁신 업체들도 포함됐다. editor@itworld.co.kr

아파치 스파크(Apache Spark)
멋진 소프트웨어가 많이 등장했지만 아파치 스파크는 여전히 데이터 애널리틱스 세계의 중심이다. 분산 컴퓨팅, 데이터 과학, 또는 머신러닝하려면 아파치 스파크로 시작하라. 2월 아파치 스파크 2.3이 출시되면서 스파크는 구조화 스트리밍 API를 지속적으로 개발하고 통합하고 개선했다. 아울러 쿠버네티스 스케줄러가 새롭게 추가되어 이 컨테이너 플랫폼 상에서 스파크를 직접 실행하기가 더욱 쉬워졌다. 전반적으로, 현재의 스파크 버전은 다듬어지고 조율되고 크롬 도금까지 입힌 느낌이다.
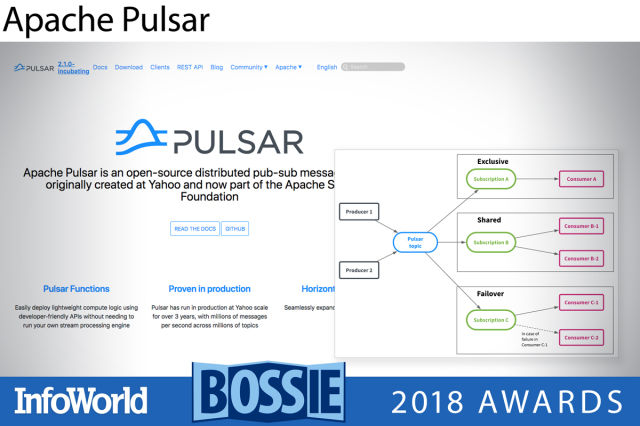
아파치 펄사(Apache Pulsar)
아파치 펄사는 야후가 개발했고 현재 아파치 프로젝트로 육성 중이다. 아파치 카프카가 여러 해 동안 차지했던 메시징의 왕좌를 노리고 있다. 여러 상황에서 아파치 카프카보다 더 빠른 입출력과 더 낮은 지연시간의 가능성을 제시하고, 개발자가 카프카에서 펄사로 비교적 손쉽게 전환할 수 있는 호환성 API를 갖추었다. 그러나 아파치 펄사의 최대의 장점은 아파치 카프카보다 훨씬 더 간소하고 견고한 운용 기능들을 제공한다는 점일 것이다. 관측성, 원거리 복제, 멀티 테넌시 문제의 처리 측면에서 특히 그렇다. 거대한 아파치 카프카 클러스터를 운영하며 힘겨워했던 기업이라면 아파치 펄사로 한숨 돌릴 수 있을 것이다.
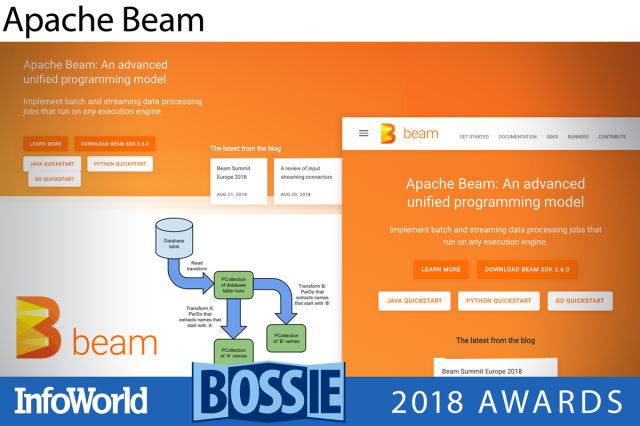
아파치 빔(Apache Beam)
여러 해에 걸쳐 배치 프로세싱과 스트림 프로세싱의 구분은 점차 사라지고 있다. 데이터의 배치 작업은 갈수록 작아져 마이크로 배치가 되고, 이들 배치에 하나로 접근하면서 스트리밍 데이터가 된다. 수많은 프로세싱 아키텍처가 이런 생각의 전환을 프로그래밍 패러다임에 구현하려고 시도해왔다. 아파치 빔은 이에 대한 구글의 응답이다. 빔은 데이터 프로세싱 파이프라인의 정의를 허용하는 여러 언어 특정적 SDK와 하나의 프로그래밍 모델을 결합시킨다. 일단 정의되면, 파이프라인은 하둡, 스파크, 플링크 등 다양한 프로세싱 프레임워크에서 실행될 수 있다. 데이터 집약적인 애플리케이션을 코딩할 때 데이터 프로세싱 파이프라인을 구축하는 데 적합하다.

아파치 솔라(Apache Solr)
아파치 솔라는 루신 인덱싱(Lucene indexing) 기술 상에 구축된 검색엔진 정도로 여겨지지만, 본질적으로 텍스트 지향 문서 데이터베이스이다. 사실 이는 대단한 데이터베이스이다. 모래밭에서 바늘을 찾는다거나, 공간 쿼리(spatial query)를 수행하는 데는 솔라가 정답이다. 최근 솔라 7 시리즈가 출시되면서 보다 분석적인 쿼리조차 고속으로 처리한다. 여러 문서를 취합해 결과를 1초 내에 반환할 수 있다. 로그 및 이벤트 데이터 지원이 개선되었다. 재해복구는 이제 양방향성이다. 그리고 클러스터 상의 로드가 증가함에 따라 새로운 자동 스케일링 기능은 단순한 관리를 허용한다. 균형을 달성하는 것 역시 서버 소프트웨어의 목표이기 때문이다.

주피터랩(JupyterLab)
주피터랩은 데이터 과학자라면 누구나 선호했던 유서 깊은 웹 기반 노트북 서버인 주피터(Jupyter)의 차세대 버전이다. 완성까지 3년이 걸린 주피터랩은 노트북 개념을 완전히 일신했다. 드래그 앤 드롭에 의한 셀 정리, 탭 노트북, 마크다운 편집의 라이브 프리뷰가 가능하고, 깃허브 같은 다른 서비스와의 통합을 용이하게 하는 개량된 확장 프로그램 시스템을 갖추었다. 2018년 말쯤이면 안정적인 1.0 릴리즈가 나올 것으로 예상되고, 2019년에 접어들면 데이터 과학은 좀 더 진화할 것이다.

KNIME 애널리틱스 플랫폼(KNIME Analytics Platform)
KNIME 애널리틱스 플랫폼은 데이터 과학 애플리케이션 및 서비스를 생성하는 오픈소스 소프트웨어이다. 비주얼 워크플로우를 생성하기 위한 드래그 앤 드롭 방식의 그래픽 인터페이스를 갖추었고, R 및 파이썬에 의한 스크립팅, 머신러닝, 아파치 스파크로의 커넥터를 지원한다. KNIME는 워크플로우에서 노드로 쓰일 수 있는 약 2,000개의 모듈을 가지고 있다. KNIME의 상용 버전도 있다. 여기에는 생산성을 증대하고 협업을 지원하는 확장 프로그램이 추가된다. 그렇다고 해서, 오픈소스 KNIME 애널리틱스 플랫폼에 인위적 제한이 있는 것은 아니고, 수억 줄에 이르는 프로젝트도 처리할 수 있다.
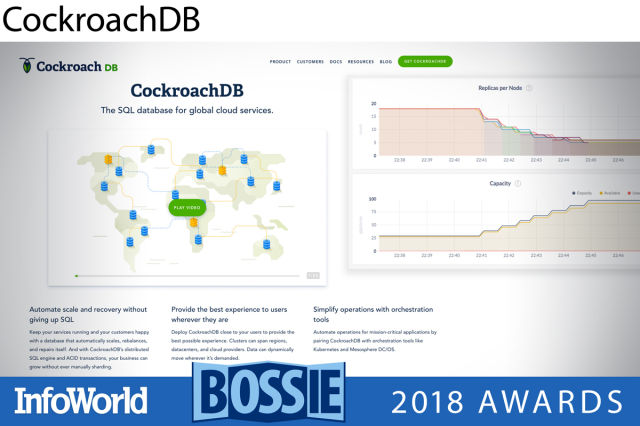
코크로치DB (CockroachDB)
코크로치DB는 트랜잭션이 가능하고 일관성 있는 키값 저장소 상에 구축된 분산 SQL 데이터베이스이다. 디스크나 머신, 랙, 심지어 데이터센터 장애에도 최소한의 지연시간과 수작업 개입없이 살아남도록 설계되었다. 2018년 1월 코크로치DB v1.13 리뷰에서 별 5개를 주었지만, 당시에도 여러 기능이 아직 부족하다는 점을 지적한 바 있다. 하지만 이제 달라졌다. 코크로치DB v2.0이 4월 출시되면서 성능이 현저하게 개선됐고, 특히 JSON 지원을 추가하며 PostgreSQL 호환성이 확장되었고, 프로덕션에서 다중 지역 클러스터를 관리하는 기능을 제공한다. 코크로치DB v2.1에서는 비용 기반 쿼리 옵티마이저(쿼리 성능의 엄청난 강화), 상관 하위 쿼리(ORM을 위한), 원활한 스키마 변경 지원을 약속하고, 엔터프라이즈 제품에는 휴면 상태 암호화가 추가된다.
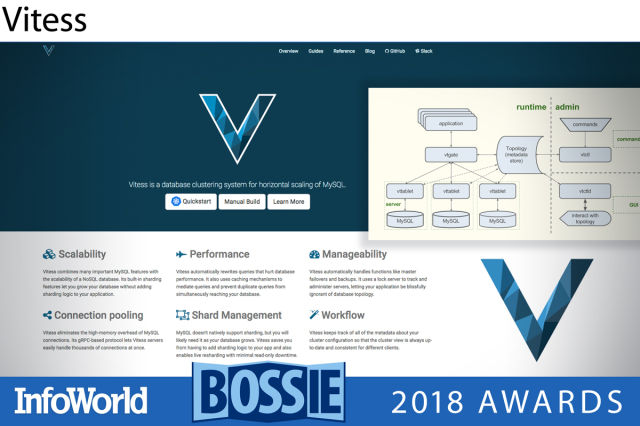
비테스(Vitess)
비테스는 일반화 샤딩(sharding)을 통한 MySQL의 수평 조정을 위한 데이터베이스 클러스터링 시스템으로, 대부분 고(Go) 언어로 작성된다. 비테스는 여러 중요한 MySQL 기능을 NoSQL 데이터베이스의 확장성과 결합하는데, 샤딩 기능을 내장해 애플리케이션에 샤딩 로직을 추가하지 않으면서 데이터베이스를 확장할 수 있다. 2011년 이래 유튜브 데이터베이스 인프라의 핵심 구성요소였고, 수천 개의 MySQL 노드를 망라할 정도로 성장했다. RAM을 많이 소모하고 노드 당 접속 수가 제한적일 수 있는 표준 MySQL 접속을 이용하는 대신, 비테스는 보다 효율적인 gRPC 기반 프로토콜을 이용한다. 아울러 데이터베이스 성능을 저해하는 쿼리를 자동으로 재작성한다. 그리고 쿼리들을 중재하고 중복 쿼리가 데이터베이스에 동시에 도달하는 것을 방지하는 캐싱 메커니즘을 이용한다.
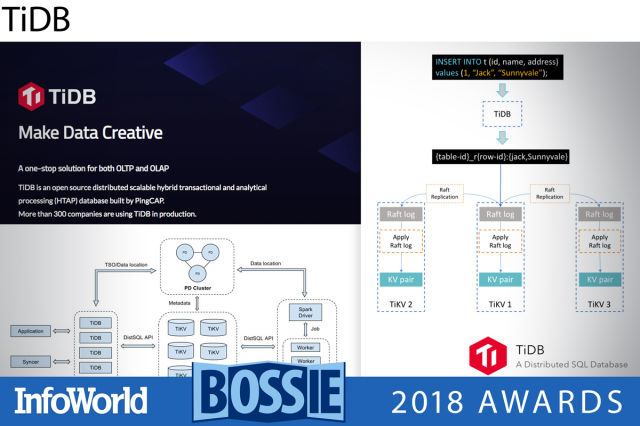
TiDB
TiDB는 MySQL과 호환되는 이른바 분산 HTAP(Hybrid Transactional and Analytical Processing) 데이터베이스이다. 트랜잭션 키-값 저장소(Key-value Store) 상에 구축되어 노드를 추가하는 방식으로 완전한 수평 확장성과 지속적인 가용성을 제공한다. TiDB는 초기에 중국에서 주로 이용되었는데, 개발자가 북경에 있기 때문이다. TiDB 소스 코드는 대부분 고 언어로 작성된다. TiDB의 최하위 계층은 록스DB(RocksDB)이다. 이는 성능을 극대화하기 위해 C++로 쓰여진 페이스북의 로그 구조 키-값 데이터베이스 엔진이다. 그 위에 래프트 컨센서스(Raft consensus) 게층, 트랜잭션 계층, 그리고 궁극적으로 MySQL 프로토콜을 지원하는 SQL 계층이 위치한다.

유가바이트 DB (YugaByte DB)
유가바이트 DB는 분산 ACID 트랜잭션, 다중- 지역 배치, 카산드라 및 레디스 API 지원을 포스트그레SQL에 결합한다. 카산드라와 비교할 때 한 가지 커다란 개선이라면 유가바이트는 일관성이 매우 강하다는 것. 반면 카산드라는 최종적으로 일관적이다. 유가바이트는 YCSB 벤치마크 상에서 오픈소스 카산드라보다 여전히 우월하지만, 조정형 일관성을 갖춘 카산드라의 상용 버전인 데이터스택스 엔터프라이즈 6(DataStax Enterprise 6)만큼 빠르지는 않다. 유가바이트는 보다 빠르고 보다 일관성 있는 분산 레디스 및 카산드라로써 유용하다. 카산드라 데이터베이스를 레디스 캐싱과 결합하는 등 여러 용도의 단일 데이터베이스 상에서 표준화를 위해 사용되기도 한다.

Neo4j
Neo4j는 독자적인 그래프 데이터베이스로서 연관 항목 네트워크를 관찰하는 작업에서 SQL이나 NoSQL 데이터베이스보다 훨씬 더 효율적이다. 그러나 그래프 모델과 사이퍼(Cypher) 쿼리 언어는 학습이 필요하다. Neo4j는 러시안 트위터 트롤, 그리고 ICIJ의 파나마 페이퍼 및 파라다이스 페이퍼를 분석하면서 다시 한번 유용성이 증명되었다. 18년에 걸쳐 개발된 Neo4j는 윈도우, 맥OS, 리눅스 상에서, 도커 콘테이너에서, VM에서, 그리고 클러스터에서 실행할 수 있는 성숙한 그래프 데이터베이스 플랫폼이다. Neo4j는 심지어 오픈소스 에디션에서도 매우 큰 그래프를 취급할 수 있고, 엔터프라이즈 에디션에서는 그래프 크기가 무제한이다. 네오4j의 오픈소스 버전은 서버 한 대로 제한된다.

인플럭스DB (InfluxDB)
인플럭스DB는 외부 의존이 없는 오픈소스 시계열 데이터베이스이다. 대량의 쓰기 및 쿼리 로드를 취급할 수 있도록 설계되어 지표 및 이벤트를 기록하고, 애널리틱스를 수행하는데 유용하다. 맥OS, 도커, 우분투/데비안, 레드햇/센트OS 및 윈도우에서 실행된다. SQL과 유사한 쿼리 언어인 빌트-인 HTTP API를 갖추었고, 100ms 미만의 실시간으로 쿼리에 응답한다는 목표를 가지고 있다.
※ 본 내용은 한국IDG(주)(http://www.itworld.co.kr)의 저작권 동의에 의해 공유되고 있습니다.
Copyright ⓒITWORLD. 무단전재 및 재배포 금지
[원문출처 : http://www.itworld.co.kr/slideshow/110963]

| 번호 | 제목 | 작성 | 조회수 |
|---|---|---|---|
| 564 | "웹 기술로 데스크톱 앱을 빠르게 개발"··· 오픈소스 툴 쿼크 등장 | 2019-07-25 | 1706 |
| 563 | '비주얼 스튜디오 코드' vs. '아톰'··· 코드 편집기 대표주자 비교 분석 file | 2019-07-08 | 2948 |
| 562 | 리뷰 | 텐서플로우 2, "더 쉬워진 머신러닝" | 2019-07-05 | 2540 |
| 561 | 마이SQL·마리아DB의 '매력 만점' 신기능 7가지 | 2019-06-28 | 2357 |
| 560 | '제법 쓸 만 하다' 무료 동영상 편집 SW 5선 | 2018-11-23 | 15070 |
| 559 | 컨테이너를 쉽고 빠르게··· 도커용 필수 도구 8가지 | 2018-11-09 | 2531 |
| 558 | '기본기 탄탄한' 오픈소스 IDS 툴 5선 | 2018-10-29 | 2691 |
| 557 | '인공지능과 환상 궁합' 프로그래밍 언어 10선 | 2018-10-26 | 3439 |
| 556 | 알아두면 좋은 비주류 자바스크립트 툴 6가지 | 2018-10-12 | 2930 |
| 555 | 2018 최고의 오픈소스 소프트웨어 : 데이터 스토리지 및 애널리틱스 | 2018-10-08 | 2720 |
0개 댓글